梦潭伙伴匹配项目总结
第一部分
技术选型
前端
- Vue3
- Vant UI组件库
- Vite脚手架
- Axios请求库
后端
- SpringBoot框架
- MySQL数据库
- MyBatis-Plus
- Redis缓存
- Redis分布式登录
- Swagger+Knife4j接口文档
- 相似度匹配算法
具体实现
使用vite进行项目的初始化,node版本需要与其匹配,可以下载nvm来进行node版本的管理。
yarn create vite
使用vant进行前端页面的布局不限于导航栏,tab栏的搭建。

设计数据库表,分析需要哪些字段。
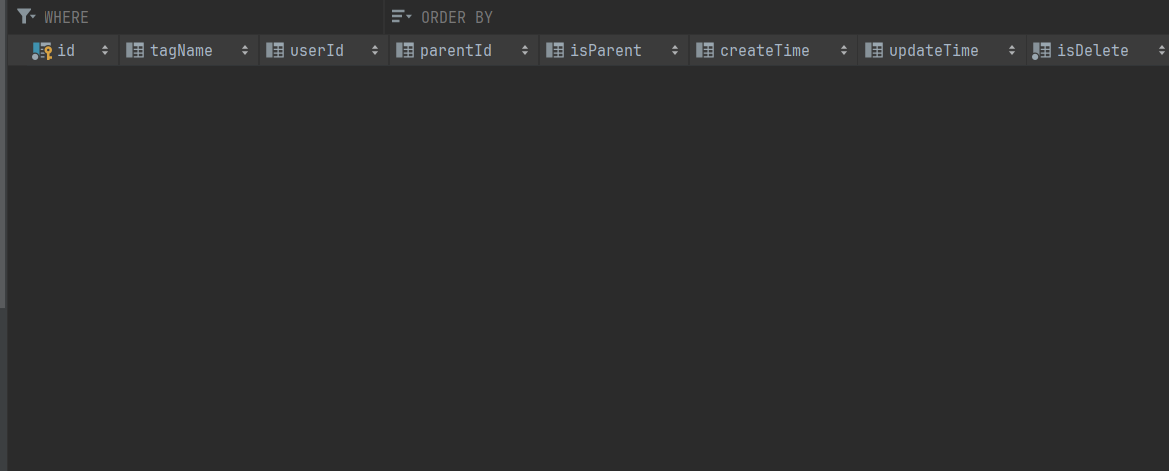
用户表的添加tag字段
- 关联表:
- 优点:查询灵活,可以正查,反查
- 缺点:需要多建一个表,多维护一个表
- 尽量减少关联查询。
- 往用户表中添加json字符串来补充tag字段。
- 优点:查询方便,不用新建表,标签是固有属性节省开发成本。
- 如果性能低可以用缓存。
- 具体情况根据需求具体分析,选择合适的。
- 关联表:
开发后端接口
搜索标签
- 允许用户传入多个标签,多个标签都存在才搜索出来,and。代码举例:like ‘%Java%’ and like ‘%C++%’。
- 允许用户传入多个标签,有任何一个标签存在就能搜索出来 or。代码举例:like ‘%Java%’ or like ‘%C++%’。
两种方式
- SQL查询(实现简单,可以通过拆分查询进一步优化)
- 内存查询(灵活,可以通过并发进一步优化)
选择场景
- 如果参数可以分析,根据用户的参数去选择查询方式,比如标签数。
- 如果参数不可分析,并且数据库连接足够、内存空间足够,可以并发同时查询,谁先返回用谁。
- 还可以SQL查询与内存计算相结合,比如先用SQL过滤掉部分Tag。
并行流和串行流
- 串行流 Stream ,并行流 parallelStream
- 并行流parallelStream缺点:parallelStream使用公共线程池,如果某一个方法耗时特别长,那么慢慢的整个线程池会都交给该方法,就没有多余的线程分配给其他任务了。
tag的判空
Optional可选类,可以减少判断的分支
tempTagNameSet = Optional.ofNullable(tempTagNameSet).orElse(new HashSet<>());
解析JSON字符串
名词解释
- 序列化:java对象转换成json
- 反序列化:把json转为java对象
java和json序列化库举例:
标签的string转json,利用gson库实现
Set<String> tempTagNameSet = gson.fromJson(tagsStr, new TypeToken<Set<User>>(){}.getType());
第二部分
前端整合路由
vue-router引入
main.ts
import {createApp} from 'vue' import {Button, Icon, NavBar, Tabbar, TabbarItem} from 'vant'; import App from './App.vue' import * as VueRouter from 'vue-router' import routes from "./config/route.ts"; const app = createApp(App); app.use(Button); app.use(NavBar); app.use(Tabbar); app.use(TabbarItem); app.use(Icon) const router = VueRouter.createRouter({ history: VueRouter.createWebHashHistory(), routes, }) app.use(router) app.mount('#app')route.ts
import Index from "../pages/Index.vue"; import Team from "../pages/Team.vue"; const routes = [ { path: '/', component: Index }, { path: '/team', component: Team }, { path: '/user', component: Team }, ] export default routes;BasicLayout.vue
<template> <van-nav-bar title="标题" left-text="返回" left-arrow> <template #right> <van-icon name="search" size="18"/> </template> </van-nav-bar> <div id="content"> <router-view/> </div> <van-tabbar route @change="onChange"> <van-tabbar-item to="/" icon="home-o" name="index">主页</van-tabbar-item> <van-tabbar-item to="/team" icon="search" name="team">队伍</van-tabbar-item> <van-tabbar-item to="/user" icon="friends-o" name="user">个人</van-tabbar-item> </van-tabbar> </template>
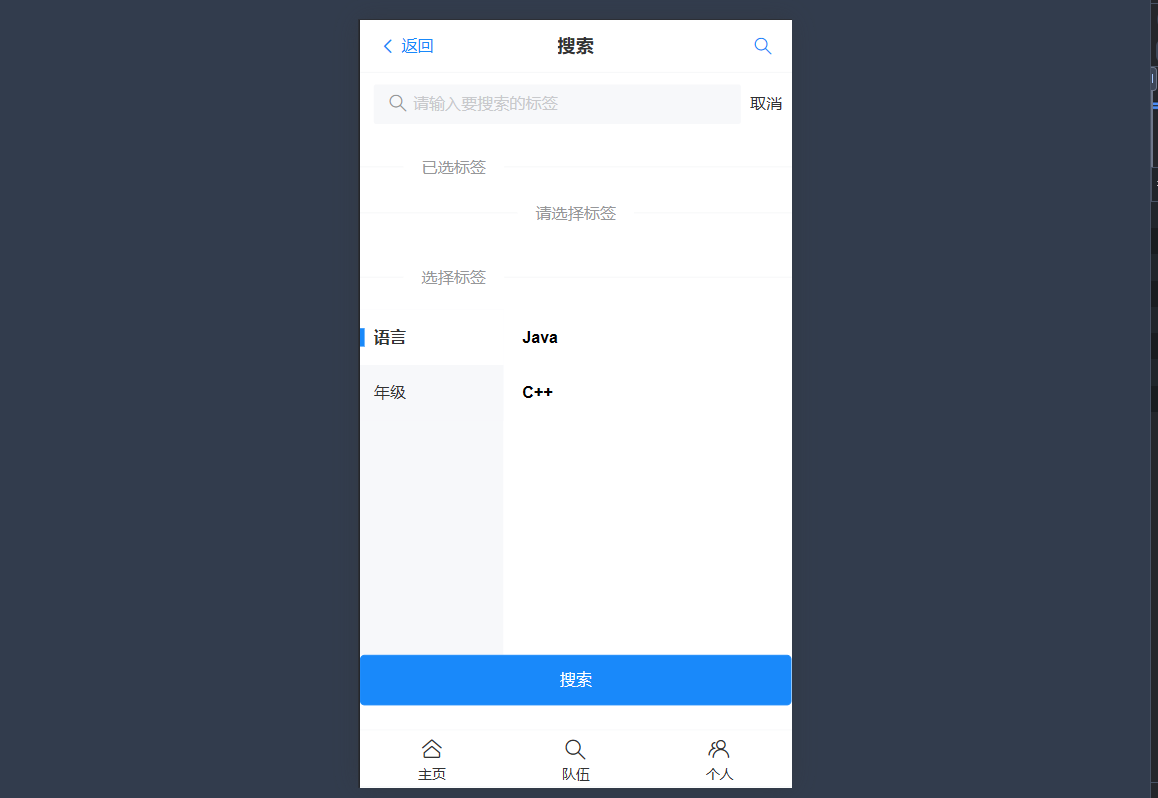
搜索页面开发
flat和flatmap
搜索的方法,展平tagList标签列表(逻辑有问题,仅用于相关方法学习)
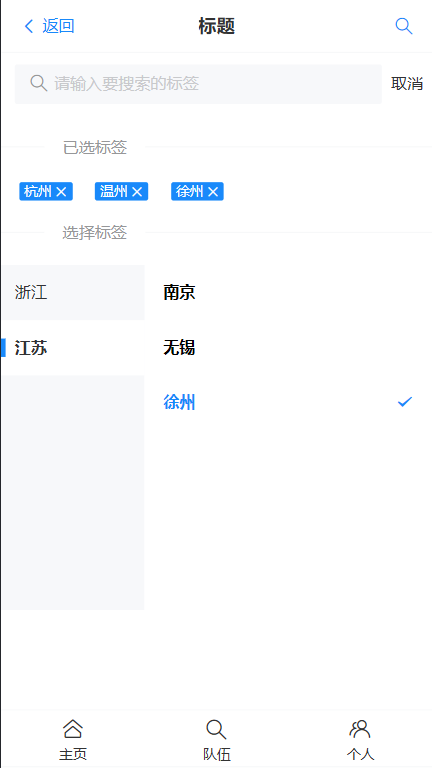
const onSearch = () => { activeIds.value = tagList .flatMap((parentTag) => parentTag.children) .filter((item) => item.text.contain(searchText.value)); };同上,正确方法
//标签列表 const originTagList = [ { text: "浙江", children: [ { text: "杭州", id: "杭州" }, { text: "温州", id: "温州" }, ], }, { text: "江苏", children: [ { text: "南京", id: "南京" }, { text: "无锡", id: "无锡" }, { text: "徐州", id: "徐州" }, ], }, ]; let tagList = ref(originTagList); const onSearch = () => { tagList.value = originTagList.map((parentTag) => { const tempChildren = [...parentTag.children]; const tempParentTag = { ...parentTag }; tempParentTag.children = tempChildren.filter((item) => item.text.includes(searchText.value), ); return tempParentTag; }); }; //清空搜索框 const onCancel = () => { searchText.value = ""; tagList.value = originTagList; };
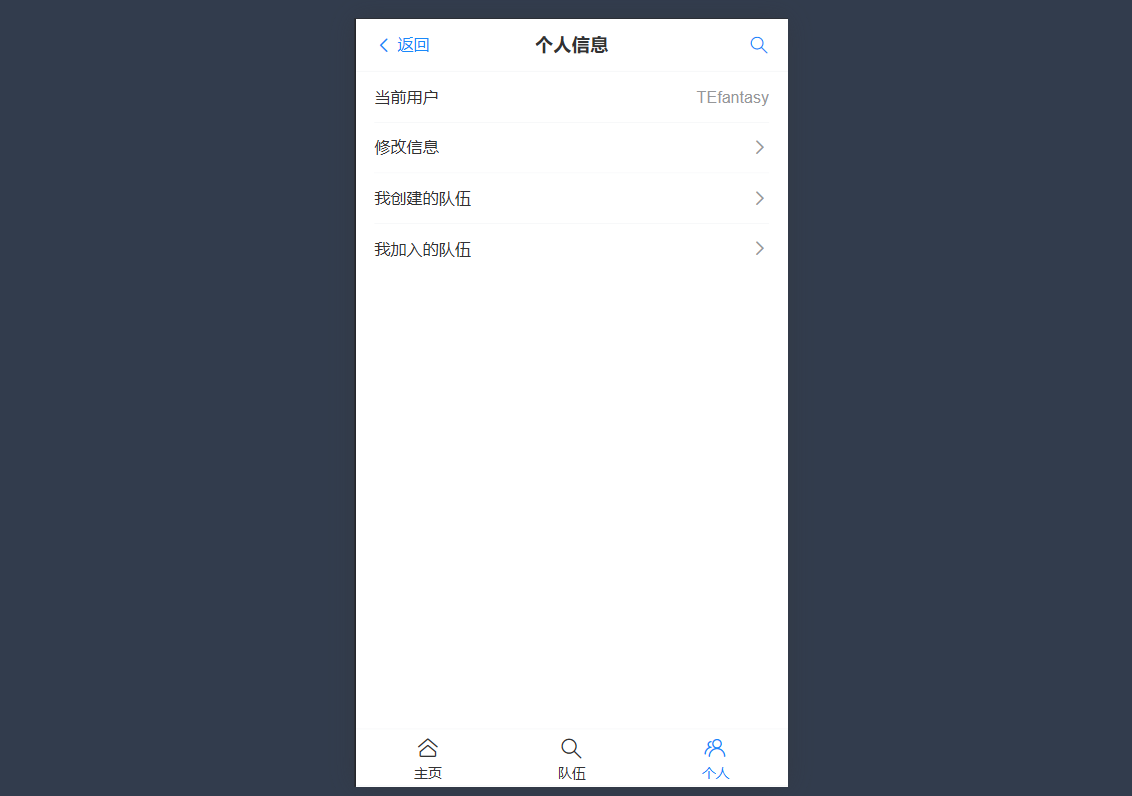
个人信息页面
定义user的用户类型
/** * 用户类型 */ export type userType = { id: number; username: string; userAccount: string; avatarUrl?: string; gender: number; phone: string; email: string; userStatus: number; userRole: number; fantasyCode: string; tags: string[]; createTime: Date; };编写前端页面
用户编辑页面
定义一个传三个参数的点击事件
@click="toEdit('avatarUrl', '头像', user.avatarUrl)"具体方法
const toEdit = (editKey: string, editName: string, currentValue: string) => { router.push({ path: "/user/edit", query: { editKey, editName, currentValue, }, }); };用户编辑页面定义传递过来的参数
const route = useRoute(); const editUser = ref({ editKey: route.query.editKey, editName: route.query.editName, currentValue: route.query.currentValue, });采用模板动态展示
<van-form @submit="onSubmit"> <van-cell-group inset> <van-field v-model="editUser.currentValue" :name="editUser.editKey" :label="editUser.editName" :placeholder="`请输入${editUser.editName}`" /> </van-cell-group> <div style="margin: 16px"> <van-button round block type="primary" native-type="submit"> 提交 </van-button> </div> </van-form>
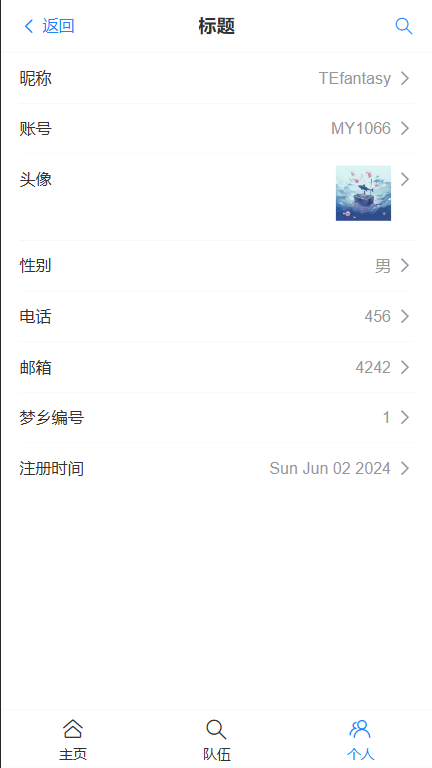
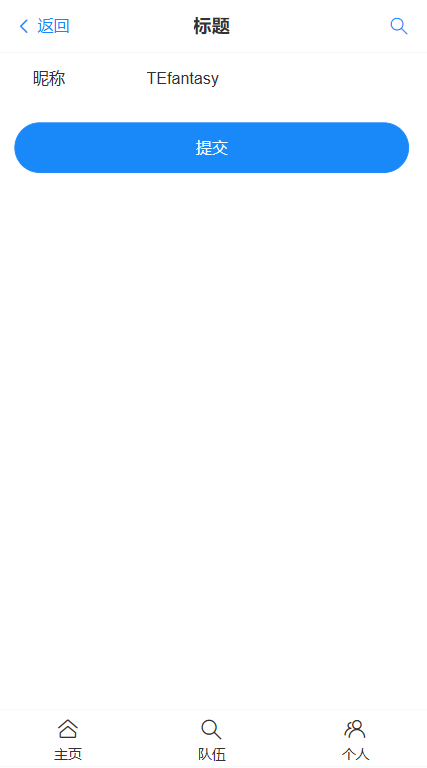
页面展示
个人信息
修改信息
搜索
第三部分
后端整合接口文档
什么是接口文档?
- 写接口信息的文档,每条信息包括
- 请求参数
- 相应参数
- 错误码
- 接口地址
- 接口名称
- 请求类型
- 请求格式
- 备注
- 谁用接口文档?一般是后端或者负责人提供,后端前端都要使用。
- 写接口信息的文档,每条信息包括
为什么需要接口文档
- 有个书面内容(背书或者归档),便于大家参考和查阅,便于沉淀和维护,拒绝口口相传
- 接口文档便于前端和后端开发对接,前后端联调介质。后端=>接口文档<=前端
- 好的接口文档支持在线调试、在线测试,可以作为工具提高我们的测试开发效率。
如何做接口文档
- 手写(比如腾讯文档,Markdown笔记)
- 自动化接口文档生成:自动根据项目代码生成完整的文档或在线调试的网页。Swagger、Postman(侧重接口管理);apifox、apipost、eolink(国产)
Swagger原理
引入依赖
自定义Swagger配置类
定义需要生成接口文档的代码位置(Controller)
注:线上环境不要把接口暴露出去。
可以通过在controller方法上添加@Api、@ApiImplicitParam(name=“name”,value=“姓名”,require=true)、@ApiOperation(value=“向客人问好”)等注解来自定义生成接口描述信息。
如果springboot version>=2.6,需要添加如下配置:
mvc: pathmatch: matching-strategy: ant_path_matcher
看上了网页信息怎么抓取到
分析网站是如何获取这些信息的,哪个接口?
curl "https://api.zsxq.com/v2/hashtags/28855251481421/topics?count=20" ^ -H "accept: application/json, text/plain, */*" ^ -H "accept-language: zh-CN,zh;q=0.9" ^ -H "origin: https://wx.zsxq.com" ^ -H "priority: u=1, i" ^ -H "referer: https://wx.zsxq.com/" ^ -H ^"sec-ch-ua: ^\^"Google Chrome^\^";v=^\^"125^\^", ^\^"Chromium^\^";v=^\^"125^\^", ^\^"Not.A/Brand^\^";v=^\^"24^\^"^" ^ -H "sec-ch-ua-mobile: ?0" ^ -H ^"sec-ch-ua-platform: ^\^"Windows^\^"^" ^ -H "sec-fetch-dest: empty" ^ -H "sec-fetch-mode: cors" ^ -H "sec-fetch-site: same-site" ^ -H "user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36" ^用程序去调用接口(JAVA/Python)。
处理(清洗)一下数据,就可以写入数据库。
流程
- 从excal导入用户数据,判重。easy excal
- 抓取写了自我介绍的同学的信息,提取出用户昵称,用户唯一id自我介绍信息‘。
- 从自我介绍中提取信息,写入数据库中。
EasyExcal
两种读取方式
- 确定表头:建立对象和表格形成映射。
- 不确定表头:每一行的数据映射为Map<String,Object>
第四部分
前端开发
- 前端页面跳转传值
- query => url searchParams,url后附加参数,传递的值长度有限。
- vuex(全局状态管理),搜索页将关键词塞到状态中,搜索结果页从状态取值。
- 前端页面跳转传值
后端开发
@GetMapping("/search/tags") public BaseResponse<List<User>> searchUserByTags(@RequestParam(required = false) List<String> tagNameList){ if (CollectionUtils.isEmpty(tagNameList)){ throw new BusinessException(ErrorCode.PARAMS_ERROR); } List<User> userList = userService.searchUsersByTags(tagNameList); return ResultUtils.success(userList); }
前后端联调
引入axios
import axios from "axios"; const myAxios = axios.create({ baseURL: 'http://localhost:8080/api', }); // 添加请求拦截器 myAxios.interceptors.request.use(function (config) { // 在发送请求之前做些什么 console.log("我要发请求了",config) return config; }, function (error) { // 对请求错误做些什么 console.log("出现错误",error) return Promise.reject(error); }); // 添加响应拦截器 myAxios.interceptors.response.use(function (response) { // 2xx 范围内的状态码都会触发该函数。 // 对响应数据做点什么 console.log("我要响应了",response) return response; }, function (error) { // 超出 2xx 范围的状态码都会触发该函数。 // 对响应错误做点什么 return Promise.reject(error); }); export default myAxios
使用钩子onMounted进行相应的配置
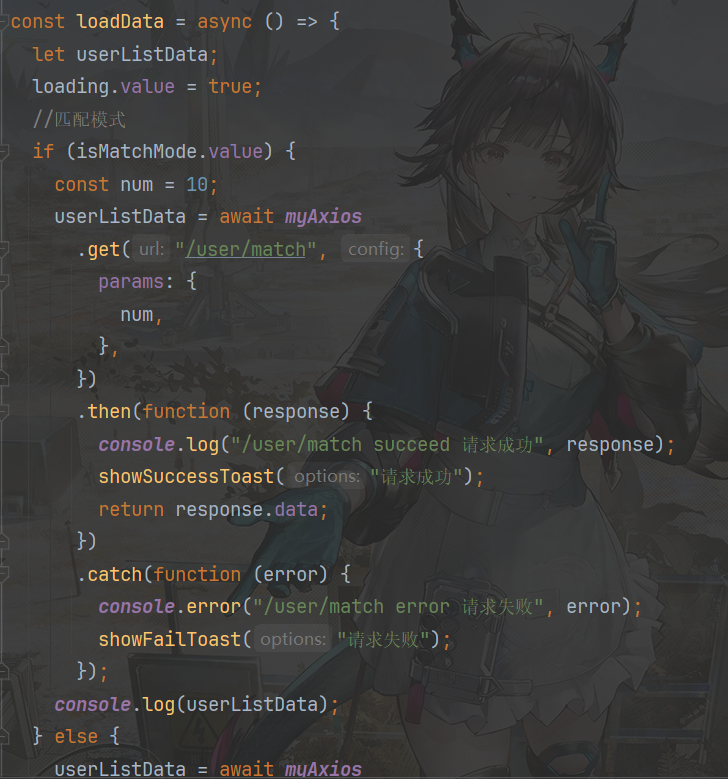
onMounted(async () => { const userListData = await myAxios .get("/user/search/tags", { params: { tagNameList: tags, }, paramsSerializer: (params) => { return qs.stringify(params, { indices: false }); }, }) .then(function (response) { console.log("/user/search/tags succeed 请求成功", response); showSuccessToast("请求成功"); return response.data?.data; }) .catch(function (error) { console.error("/user/search/tags error 请求失败", error); showFailToast("请求失败"); }); if (userListData) { userListData.forEach((user) => { if (user.tags) { user.tags = JSON.parse(user.tags); } }); userList.value = userListData; } });
注意使用qs对传值进行序列化
对tags进行json数组的转换
后端跨域配置添加注解
@CrossOrigin(origins = {"http://localhost:5173"})
第五部分
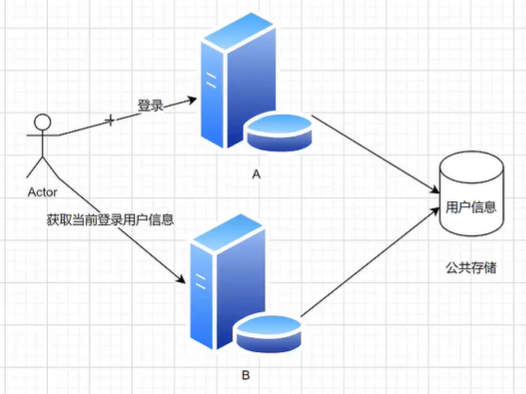
用户登录(session共享分布式登录)
种session的时候注意范围,可以在servlet下配置cookie.domain,如果要共享cookie,可以种一个更高层的公共域名
多服务器时登录解决方案
如何做?
- Redis(基于内存的K/V数据库)选择Redis,因为用户信息读取/是否登录的判断极其频繁,Redis基于内存,读写性能高,简单的单机数据 qps 5w~10w
- MySQL
- 文件服务器ceph
Redis安装
下载windows版本redis
redis管理工具 quick redis:https://quick123.net/
引入redis,注意版本号对应
<!-- https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-data-redis --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> <version>2.6.13</version> </dependency>引入spring-session和redis的整合,使得自动将session存储到redis中:
<!-- https://mvnrepository.com/artifact/org.springframework.session/spring-session-data-redis --> <dependency> <groupId>org.springframework.session</groupId> <artifactId>spring-session-data-redis</artifactId> <version>2.6.4</version> </dependency>修改spring-session存储配置spring.session.store-type
默认是none,表示存储在单台服务器
store-type:redis,表示从redis读写session
后端开发
用户更新信息的controller层方法
@PostMapping("/update") public BaseResponse<Integer> updateUser(@RequestBody User user, HttpServletRequest request) { //判断是否为空 if (user == null) { throw new BusinessException(ErrorCode.PARAMS_ERROR); } User loginUser = userService.getLoginUser(request); //判断权限,触发更新 Integer result = userService.updateUser(user, loginUser); return ResultUtils.success(result); }使用JSON的请求方式时,Post请求的变量需要加上@RequestBody。
优化service层方法,新增getLoginUser()以及updateUser()两个方法,将判断是否为管理员的isAdmin()方法放入service层,使得多个地方可以复用。
@Override public int updateUser(User user, User loginUser) { long userId = user.getId(); if (userId <= 0) { throw new BusinessException(ErrorCode.PARAMS_ERROR); } //如果是管理员,更新任意用户 //如果不是管理员,只能更新自己 if (!isAdmin(loginUser) && userId != loginUser.getId()) { throw new BusinessException(ErrorCode.NO_AUTH); } User oldUser = userMapper.selectById(userId); if (oldUser == null) { throw new BusinessException(ErrorCode.NULL_ERROR); } return userMapper.updateById(user); }
前端开发
利用自封装的axios更新用户修改页面
const onSubmit = async () => { const res = await myAxios.post('/user/update', { 'id':1, [editUser.value.editKey as string]: editUser.value.currentValue, }) if (res.code===0 && res.data>0){ showSuccessToast("修改成功"); router.back(); }else { showFailToast("修改失败"); } };完善之前开发未完成的登录部分
用户个人信息部分
onMounted(async () => { const res = await myAxios.get("/user/current"); if (res.code === 0) { console.log(res) user.value = res.data.data; }else{ showFailToast("获取失败"); } });
前后端联调
登录时前端请求要携带cookie,后端需要允许跨域cookie的携带
在自己的axios配置中添加
//携带cookie myAxios.defaults.withCredentials = true;在后端的controller层前配置@CrossOrigin,其中添加如下配置
@CrossOrigin(origins = {"http://localhost:5173"},allowCredentials = "true")
将获取当前登录用户进行封装
import { getCurrentUserState, setCurrentUserState } from "../states/user.ts"; import myAxios from "../plugins/myAxios.ts"; export const getCurrentUser = async () => { // const currentUser = getCurrentUserState(); // if (currentUser){ // return currentUser; // } const res = await myAxios.get("/user/current"); if (res.code === 0) { setCurrentUserState(res.data); return res.data; } return null; };对用户登录状态进行缓存
import { userType } from "../models/user"; let currentUser: userType; const setCurrentUserState = (user: userType) => { currentUser = user; }; const getCurrentUserState = () => { return currentUser; }; export { setCurrentUserState, getCurrentUserState };
第六部分
主页开发
通过list列表,将默认推荐信息展示在主页。
抽象列表组件,方便复用
<template> <van-card v-for="user in props.userList" :desc="user.profile" :title="`${user.username}(${user.fantasyCode})`" :thumb="user.avatarUrl" > <template #tags> <van-tag plain type="primary" v-for="tag in user.tags" style="margin-right: 5px; margin-top: 5px" >{{ tag }} </van-tag> </template> <template #footer> <van-button size="small">联系我</van-button> </template> </van-card> </template> <script setup lang="ts"> import { userType } from "../models/user"; interface UserCardListProps { userList: userType[]; } const props = withDefaults(defineProps<UserCardListProps>(), { userList: [], }); </script> <style scoped></style>
批量导入数据
- 用可视化界面:适合一次性导入,数据量可控
- 写程序:for循环,建议分批,不要一把梭哈(用接口控制)
- 执行SQL语句:适用于小数据量
编写一次性任务
- 问题
- 建立和释放数据库链接(批量查询)
- for循环是绝对线性的
- 问题
第七部分
数据查询慢怎么办:提前把数据取出来保存好(通常保存到读写更快的介质,比如内存),就可以更快的读写。
缓存的实现
Redis(分布式缓存)
memcached(分布式)
Etcd(云原生架构的一个分布式存储)
ehcache(单机)
本地缓存(Java内存Map)
Caffeine(Java内存缓存,高性能)
Google Guava
Redis
键值对存储系统
Redis数据结构
String字符串类型:name:“tefantasy”
List列表:name[“tefantasy”,“MY”,“tefantasy”]
Set集合:name[“tefantasy”,“MY”](值不能重复)
Hash哈希:nameAge{“tefantasy”:1,“MY”:2}
Zset集合:names:{tefantasy-9,MY-12}
高级数据结构
- bloomfilter(布隆过滤器,主要从大量数据中快速过滤值,比如邮件黑名单拦截)
- geo(计算地理位置)
- hyperloglog(大数据统计)
- pub/sub(发布订阅,类似消息队列)
- BitMap(把数据按照010101类似的方式存储)
自定义RedisTemplate
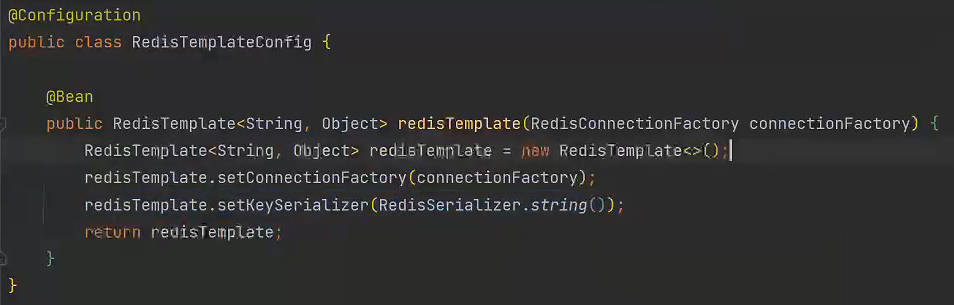
注:引入一个库时,先编写测试类。
设计缓存Key
- 不同用户看到的数据不同
- systemId:moduleId:func
(不要和别人冲突) - mengtan:user:recommend
- redis内存不能无限叠加,一定要设置过期时间
缓存预热
- 缓存预热优点:可以让用户始终访问很快
- 缺点:
- 增加开发成本(需要额外的开发设计)
- 预热的时机和时间如果错了,有可能你缓存的数据不对或者太老
- 需要占用额外的空间
- 如何缓存预热
- 定时
- 模拟触发(手动触发)
- 注:分析优缺点的时候,要打开思路,从整个项目从0到1的链路上去分析。
- 实现
- 用定时任务,每天刷新所有用户的推荐列表
- 注意点:
- 缓存预热的意义(新增少,总用户多)
- 缓存的空间不能太大,要预留给其他缓存空间
- 缓存数据的周期(此处每天一次)
定时任务实现
Spring Scheduler(springboot默认整合了)
Quartz(独立于Spring存在的定时任务框架)
XXL-Job之类的分布式任务调度平台(界面+SDK)
- 第一种方式:
- 主类开启@EnableScheduling
- 给要定时执行的方法添加@Scheduling注解,指定cron表达式或者执行频率
JAVA里的实现方式
Spring Data Redis
引入
<!-- https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-data-redis --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> <version>2.6.13</version> </dependency>配置Redis地址
#redis配置 redis: port: 6379 host: localhost database: 0
Jedis
- 独立于spring操作redis的Java客户端
Lettuce
- 高阶的操作redis的java客户端
- 异步,支持连接池
Redission
- 分布式的操作redis的java客户端,让你像使用本地集合一样使用redis
对比

控制定时任务的执行
如何做:
分离定时任务和主程序,只在一个服务器运行定时任务,成本太大
写死配置,每个服务器都执行定时任务,只有固定ip可以继续执行下去,成本小,但是ip可能不是固定的,写的太死了
动态配置,配置是可以轻松的、很方便的更新(代码无需重启),但是只有ip符合配置条件的才真实执行业务逻辑
数据库
Redis
配置中心(Nacos、Apollo、spring cloud config)
问题:服务器多了,ip还是不可控很麻烦,需要人工修改。
分布式锁:只有抢到锁的服务器才能执行业务逻辑。坏处:增加成本。好处:不用手动配置,多少个服务器都一样
锁
有限资源的情况下,控制同一时间(段)只有某些线程(用户/服务器)才能访问到资源。
Java实现锁:synchronized关键字、并发包的类
问题:只对单个JVM有效
分布式锁
- 为啥需要分布式锁?
- 有限资源的情况下,控制同一时间(段)只有某些线程(用户/服务器)才能访问到资源。
- 单个锁只对单个JVM有效
- 为啥需要分布式锁?
分布式锁实现的关键
抢锁机制
- 怎么保证同一时间只有1个服务器抢到锁?
- 核心思想:先来的人先把数据改成自己的标识(服务器ip),后来的人发现标识已经存在,就抢锁失败,继续等待。等先来的人执行方法结束,把标识清空,其他人继续抢锁。
- MySQL数据库:select for update 行级锁(最简单)(乐观锁)
- Redis实现:内存数据库,读写速度快。支持setnx、lua脚本,比较方便我们实现分布式锁。
- setnx:set if not exists 如果不存在,则设置;只有设置成功才会返回true,否则返回false。
注意事项
- 用完锁要释放(腾地方)
- 锁一定要加过期时间
- 如果方法执行时间过长,锁提前过期时
- 会出现的问题:
- 连锁效应:释放别人的锁
- 还会存在多个方法同时执行的情况。
- 解决方法:
- 续期
- 会出现的问题:
- 释放锁的时候,有可能先判断出是自己的锁,然后锁过期了,最后还是释放了别人的锁。
- 解决办法:使用redis的原子操作,在判断执行时不允许再设置锁。用redis+lua脚本实现。
第八部分
Redisson实现分布式锁
Redisson是一个java操作redis的客户端,提供了大量的分布式数据集来简化对redis的操作和使用,可以让开发者像使用本地集合一样使用redis,完全感知不到redis的存在。
两种引入方式
- spring boot starter引入(不推荐)
- 直接引入
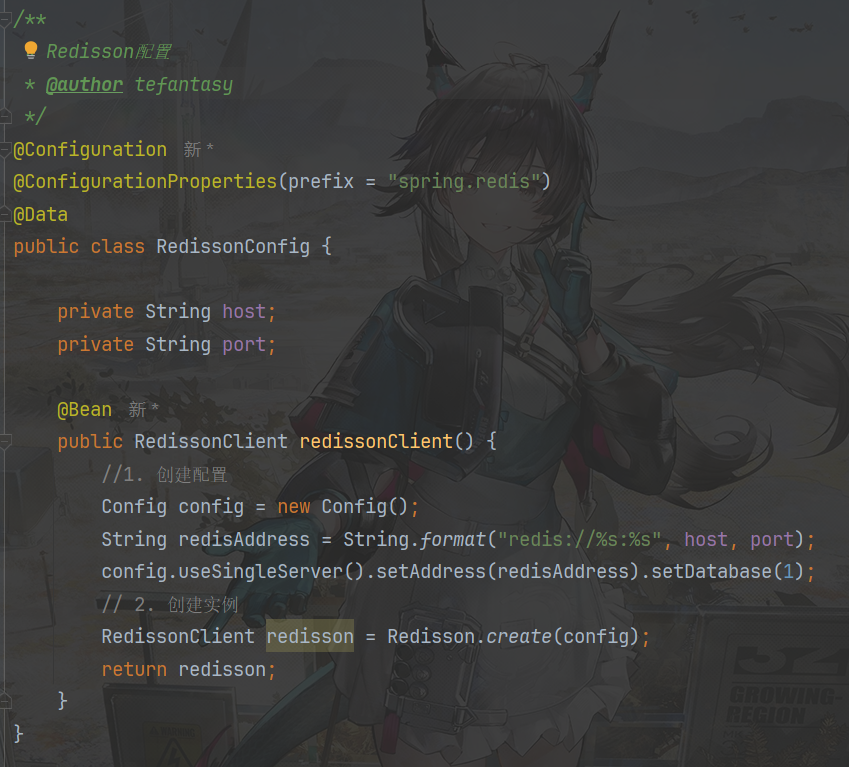
首先对Redisson进行配置
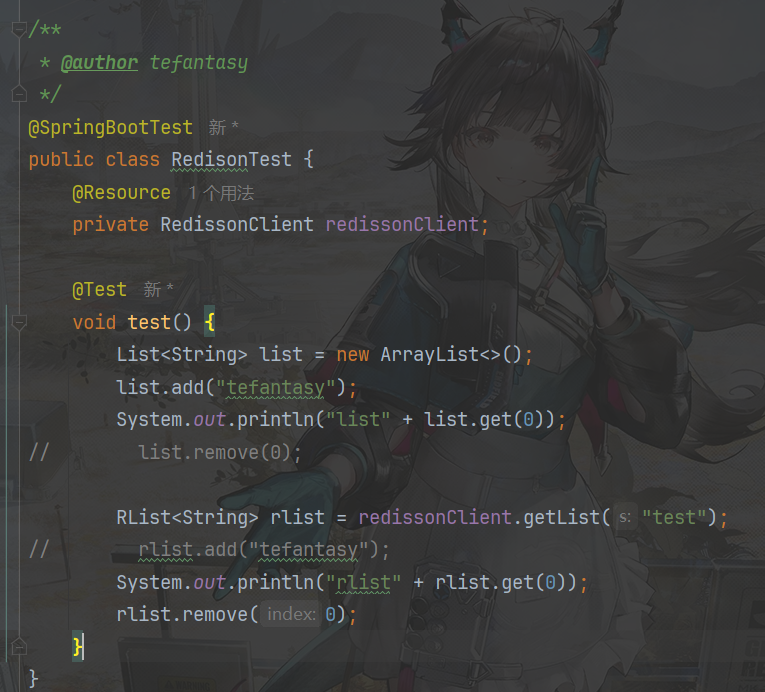
再进行测试
测试通过后,编写对应的使用代码
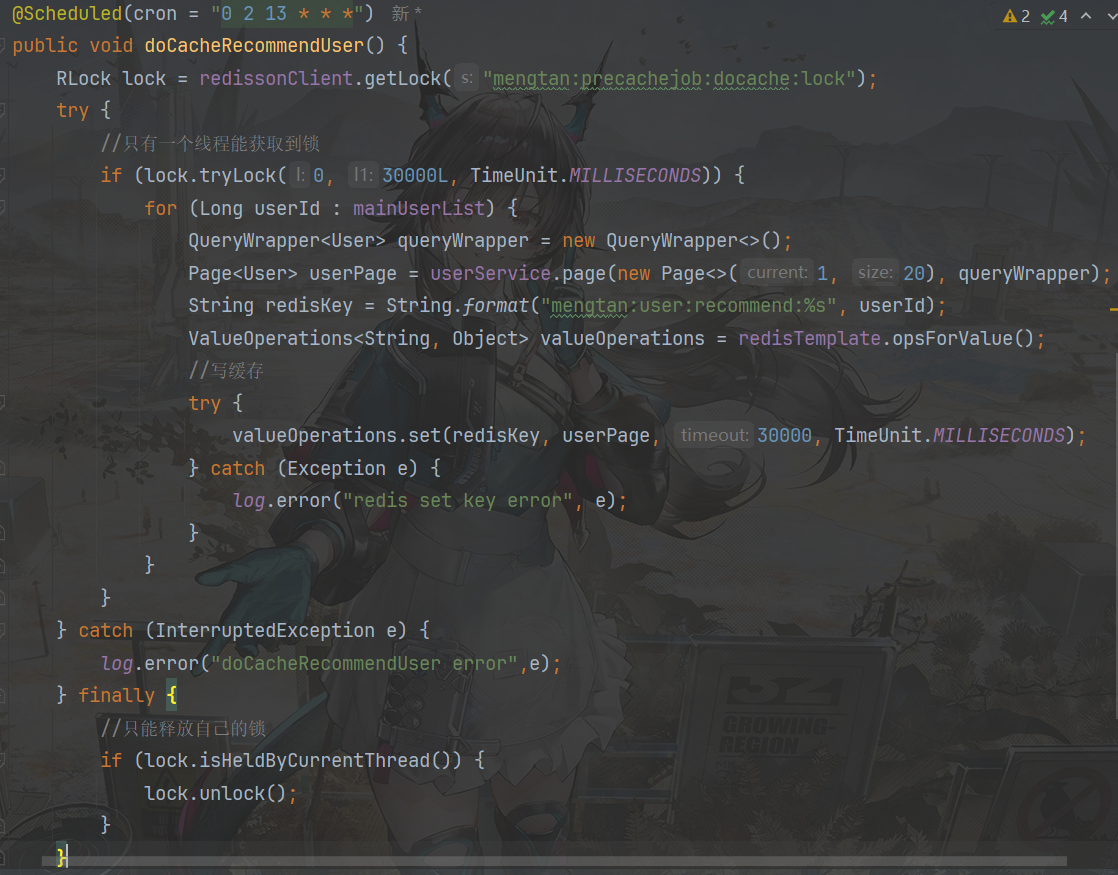
定时任务+锁
- waitTime设置为0,只抢一次,抢不到就放弃。
- 注意释放锁要写在finally中。
看门狗机制
redisson中提供的续期机制
- 开一个监听线程,如果方法还没执行完,就帮你重置redis锁的过期时间。
- 原理:
- 监听当前线程,默认续期时间是30s,每10秒续期一次(补充道30s)
- 如果线程挂掉(注意debug模式也会被当成服务器宕机),则不会续期
第九部分
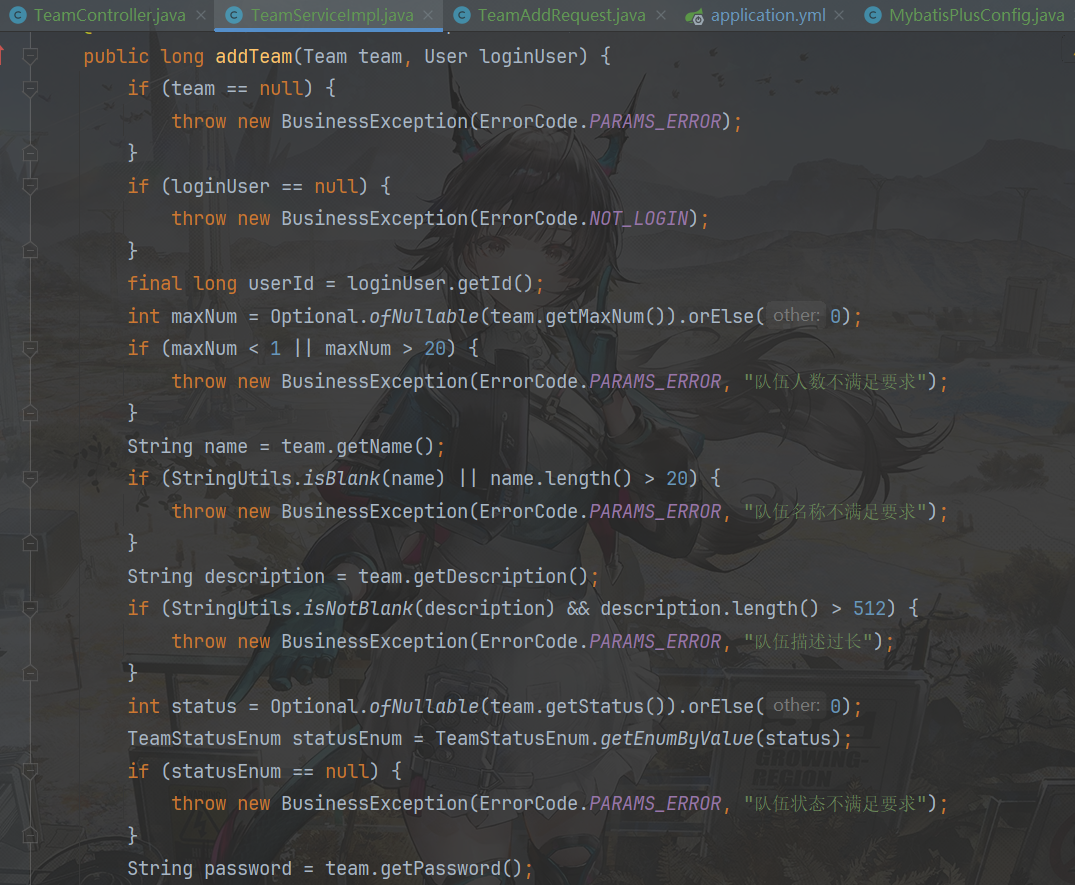
需求分析
数据库表设计
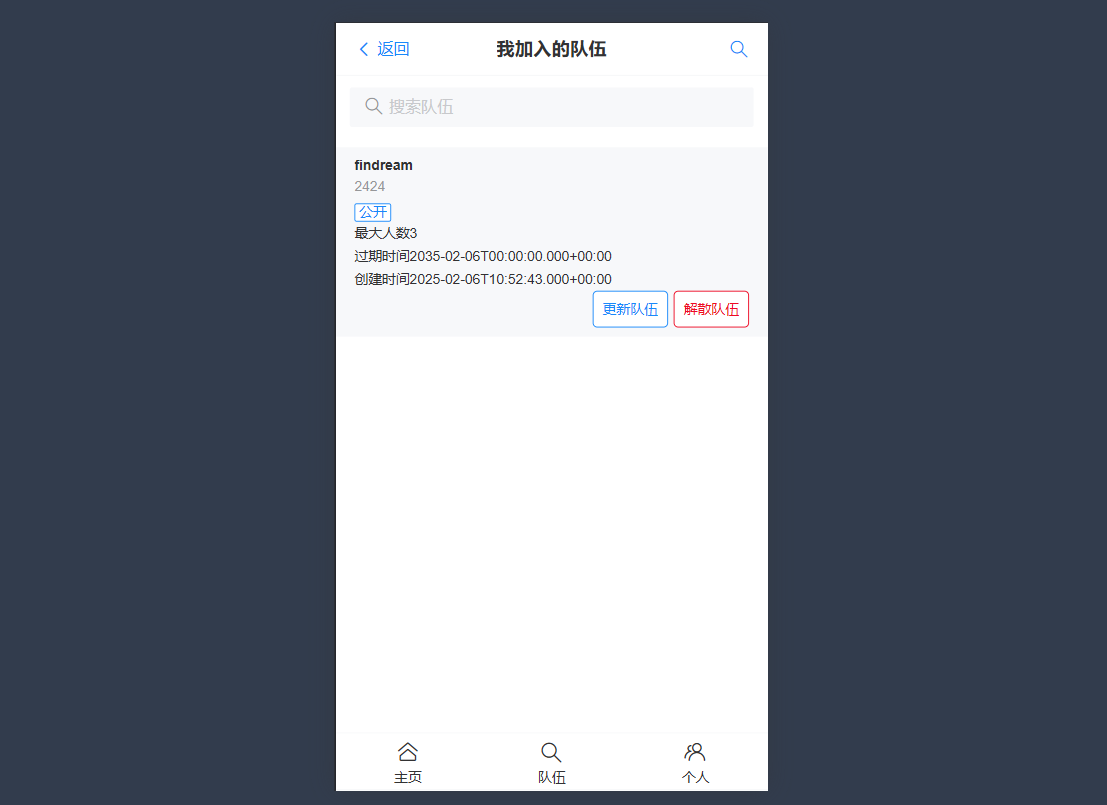
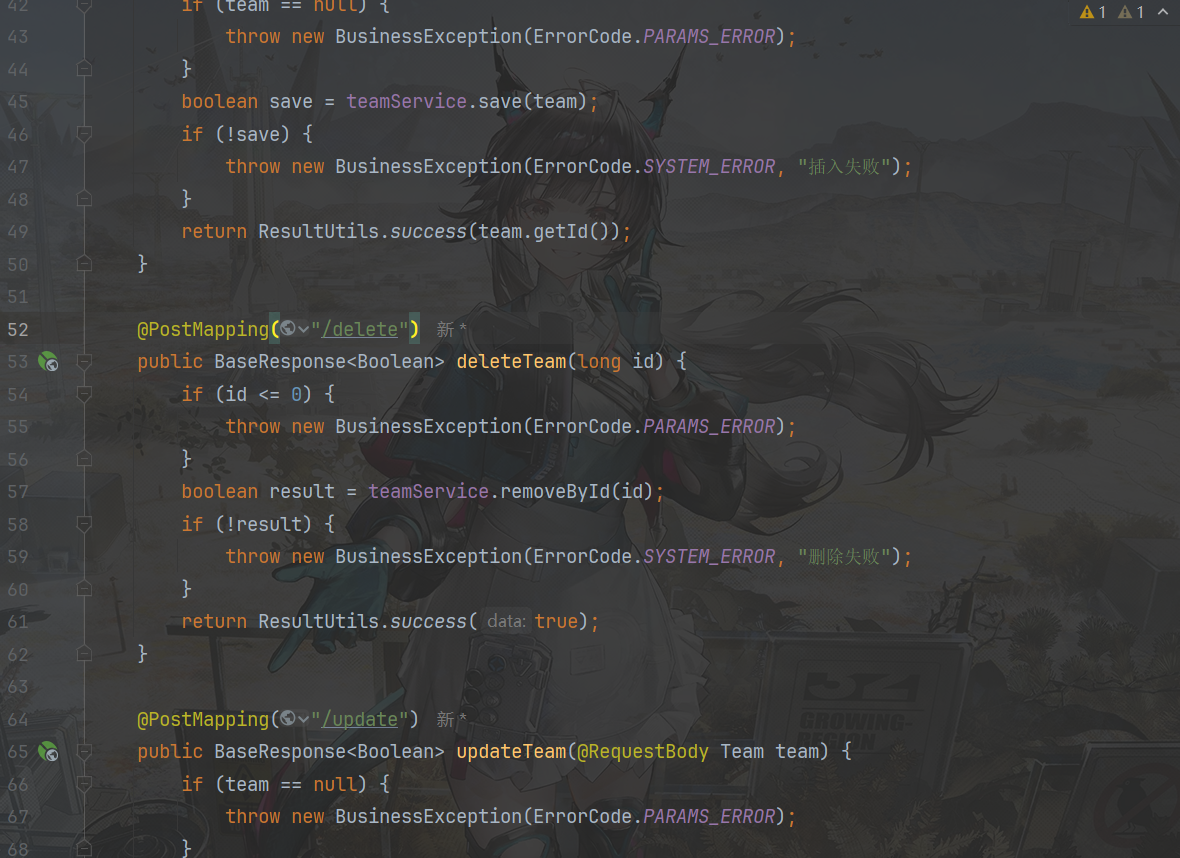
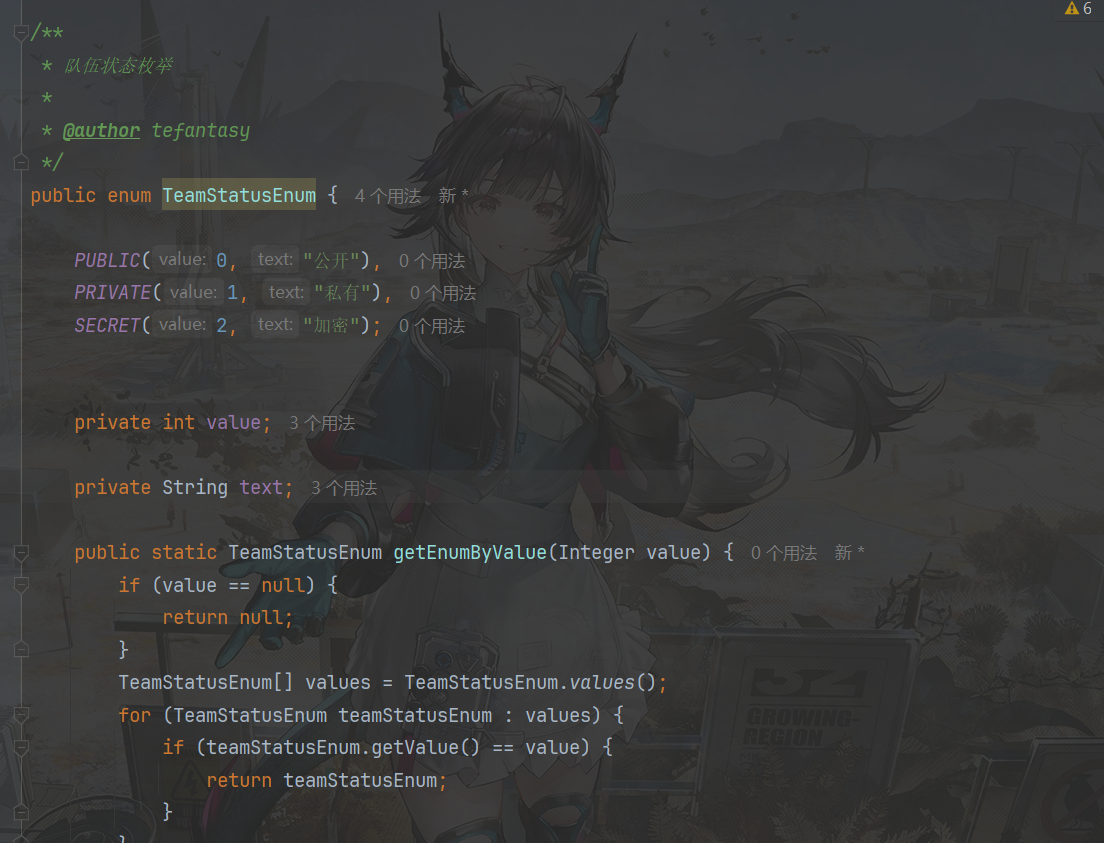
create table team ( id bigint auto_increment comment 'id' primary key, name varchar(256) not null comment '队伍名称', description varchar(1024) null comment '描述', maxNum int default 1 not null comment '最大人数', expireTime datetime null comment '过期时间', userId bigint comment '用户Id', status int default 0 not null comment '状态,0-公开,1-私有,2-加密', password varchar(512) null comment '密码', createTime datetime default CURRENT_TIMESTAMP not null comment '创建时间', updateTime datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '更新时间', isDelete tinyint default 0 not null comment '是否删除' )comment '队伍'; create table user_team ( id bigint auto_increment comment 'id' primary key, userId bigint comment '用户Id', teamId bigint comment '队伍Id', joinTime datetime null comment '加入时间', createTime datetime default CURRENT_TIMESTAMP not null comment '创建时间', updateTime datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '更新时间', isDelete tinyint default 0 not null comment '是否删除' )comment '用户队伍关系';实现增删改查,细化判断条件
例图:
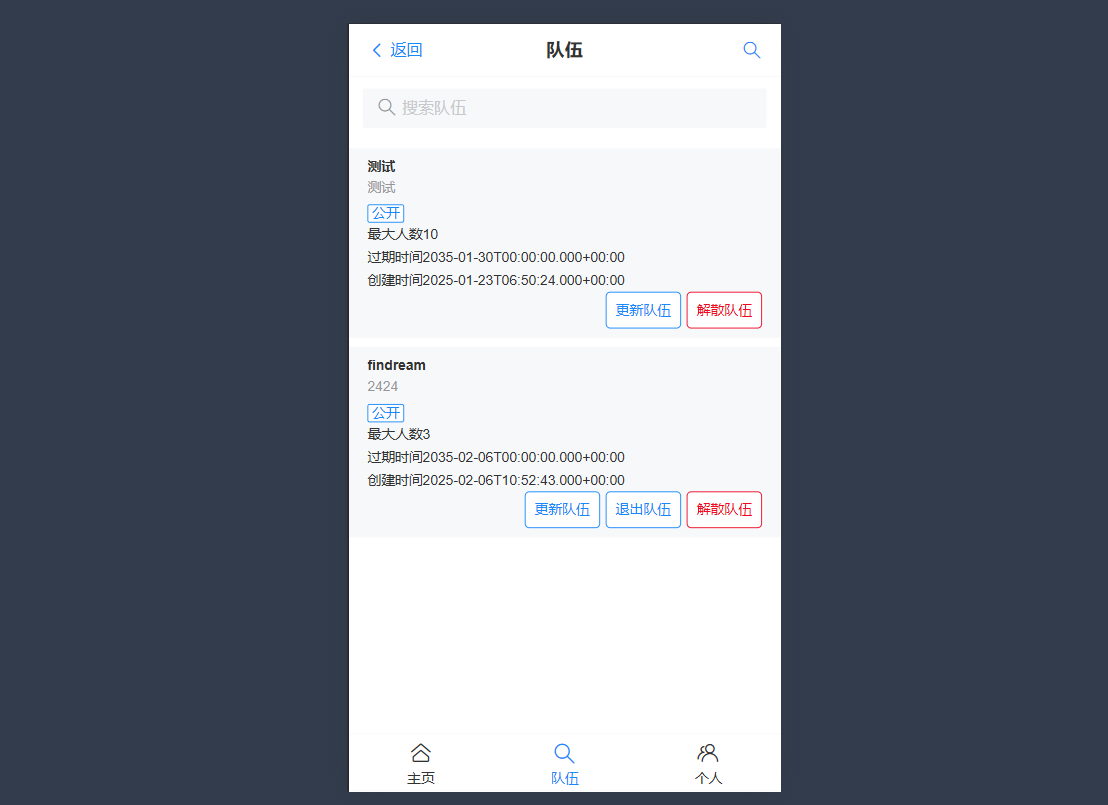
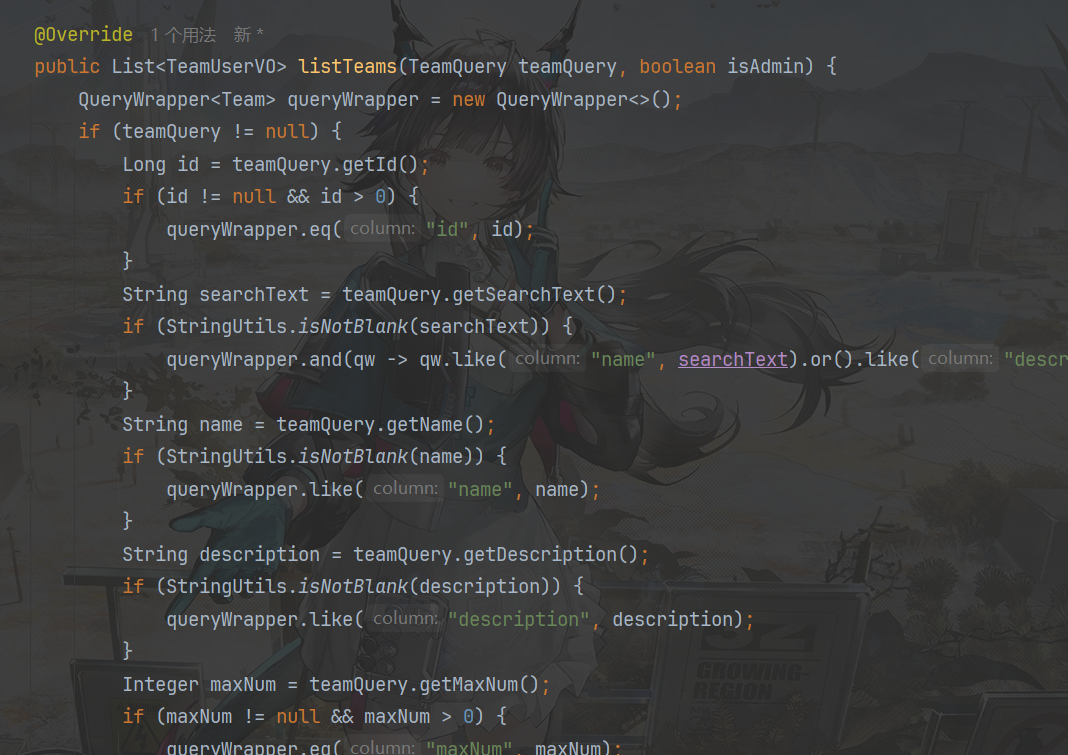
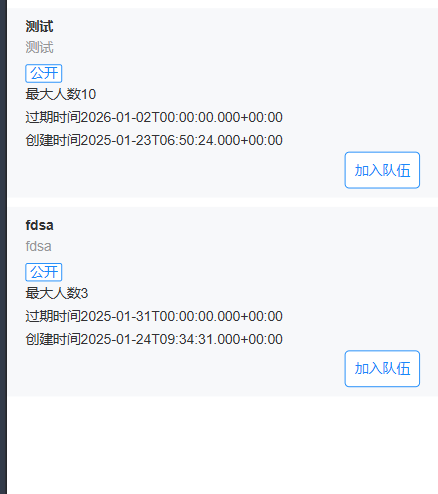
查询队伍列表需求分析
- 分页展示队伍列表,根据名称搜索队伍,信息流中不展示已过期的队伍
- 从请求参数中取出队伍名称,如果存在则作为查询条件
- 不展示已过期的队伍(根据过期时间筛选)
- 关联查询已加入队伍的用户信息
- 例图:
- 分页展示队伍列表,根据名称搜索队伍,信息流中不展示已过期的队伍
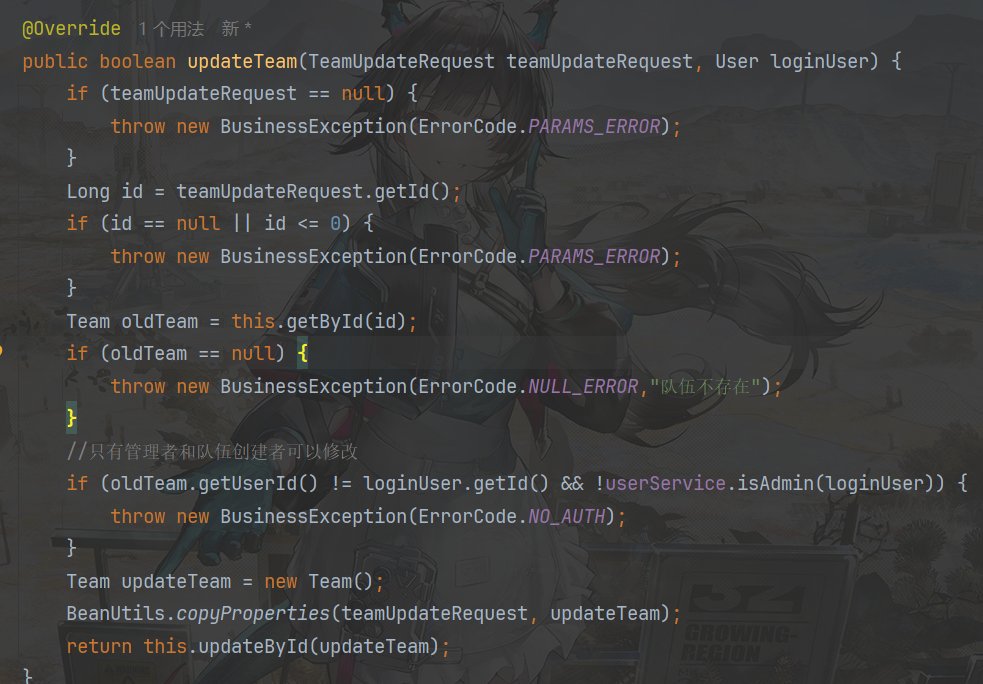
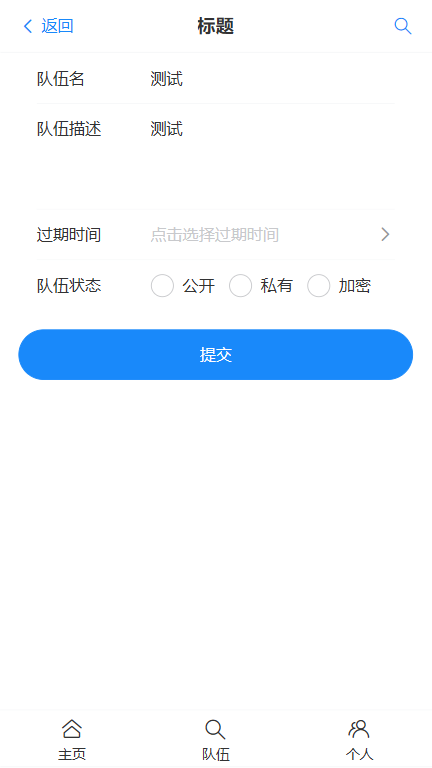
更新队伍信息
例图
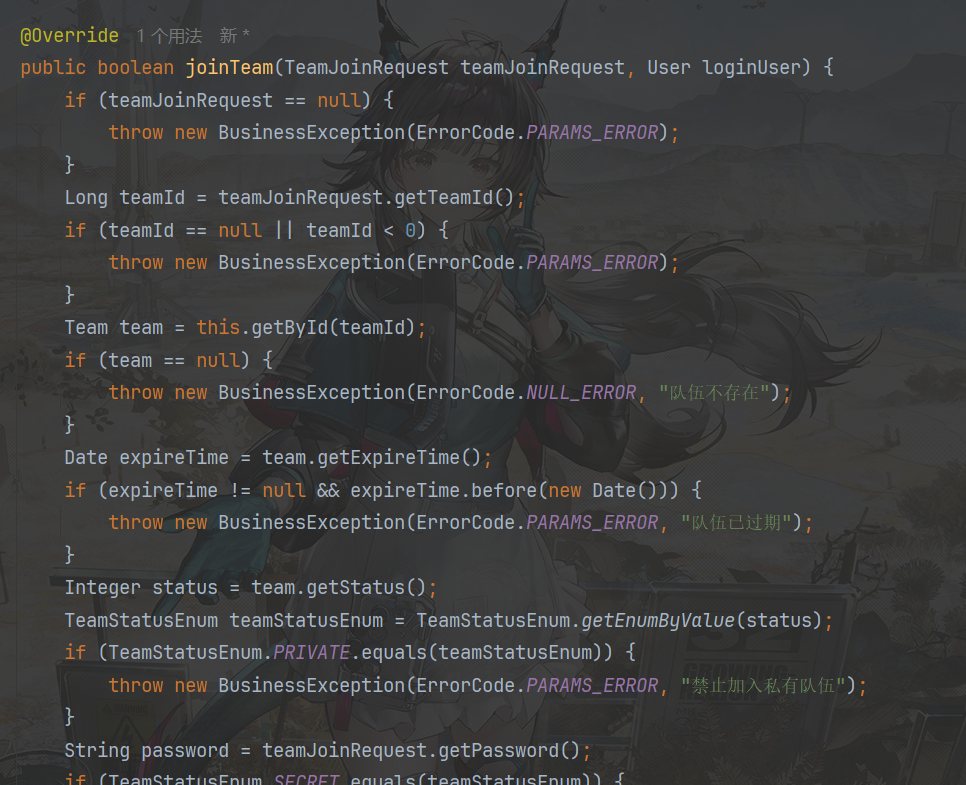
加入队伍细化判断
- 例图
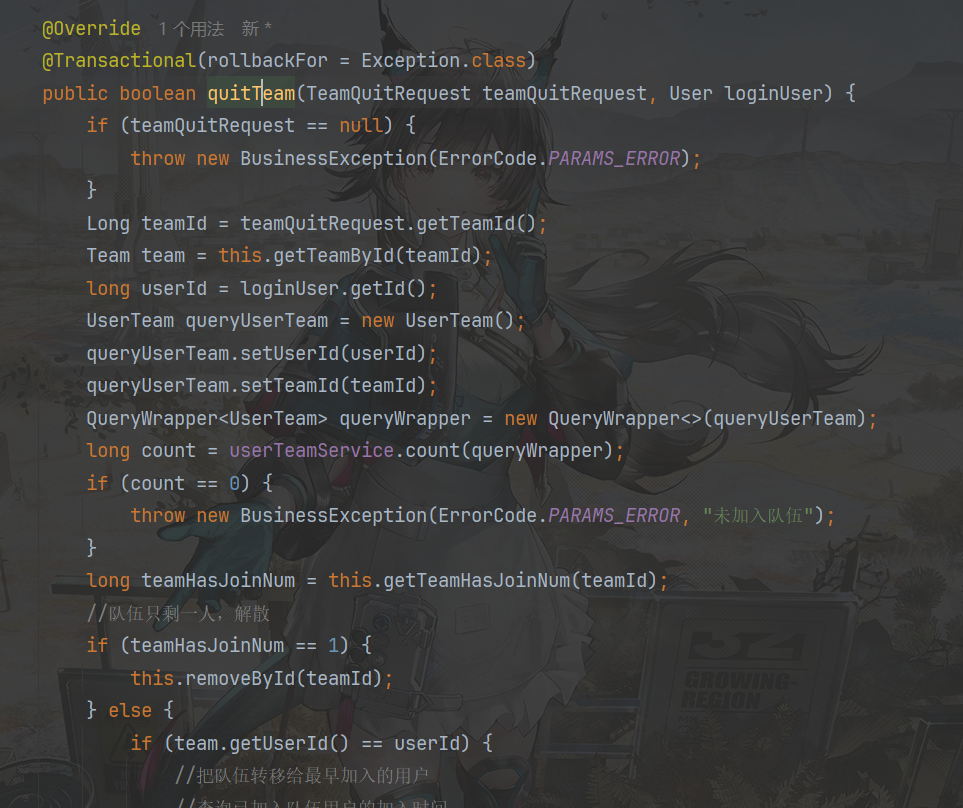
退出队伍细化判断
- 例图
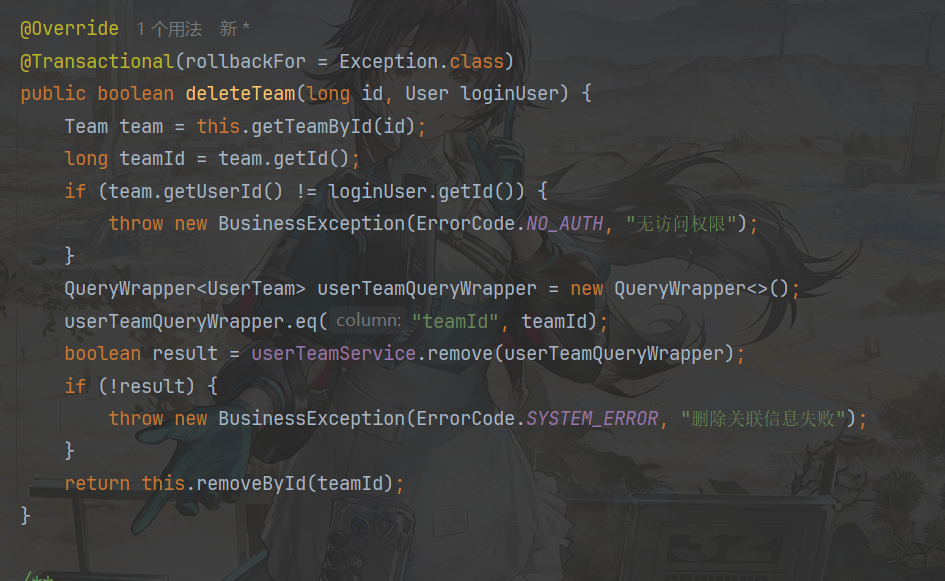
解散队伍细化判断
- 例图
注意
对数据库有多次操作的方法需要加上事务管理注解,保持一致性。
要么数据操作都成功,要么都失败
@Transactional(rollbackFor = Exception.class)

第十部分
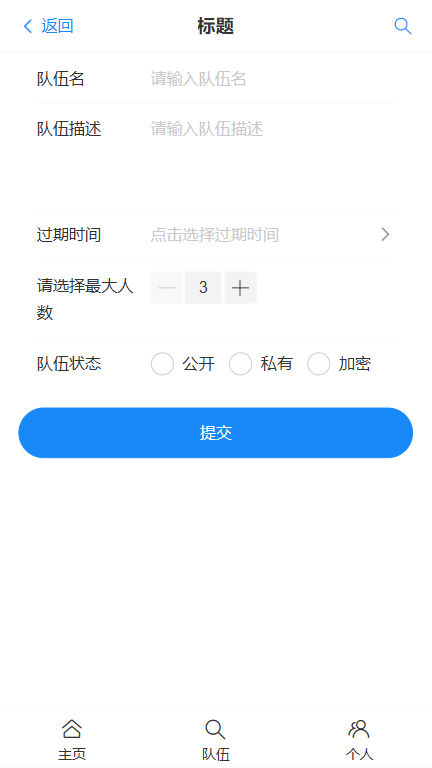
创建队伍页面
页面例图
注意:由于vant4的DateTimePicker组件有改动,数据类型不是数组则不能弹出。因此在方法中进行转换。同时为了确保弹出,该位置绑定的数据单独设置为数组。在方法中转换后赋值给表单。示例:
const DataToString = ref({ expireTime: [], }); const showPicker = ref(false); const result = ref(""); const pickerValue = ref([]); const minDate = new Date(); const onConfirm = ({ selectedValues }) => { const formattedDate = `${selectedValues[0]}-${selectedValues[1].padStart(2, "0")}-${selectedValues[2].padStart(2, "0")}`; result.value = formattedDate; addTeamData.value.expireTime = formattedDate; pickerValue.value = selectedValues; showPicker.value = false; };
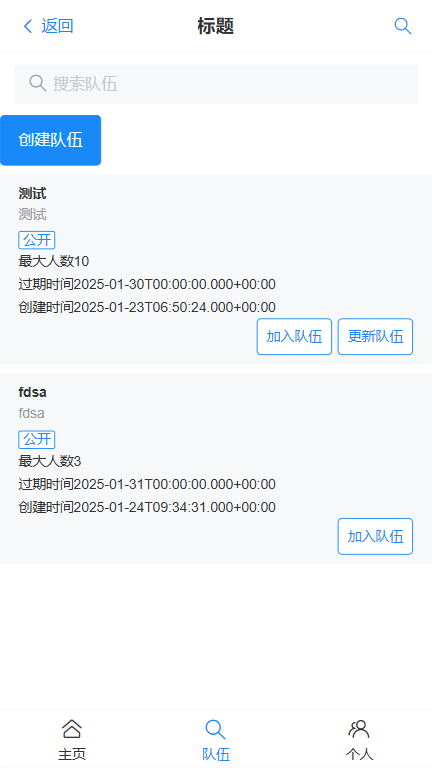
浏览队伍以及加入队伍页面(待优化)
- 例图
- 例图
权限控制
前端不同页面怎么传递数据
更新队伍页面
获取当前用户已加入和创建的队伍
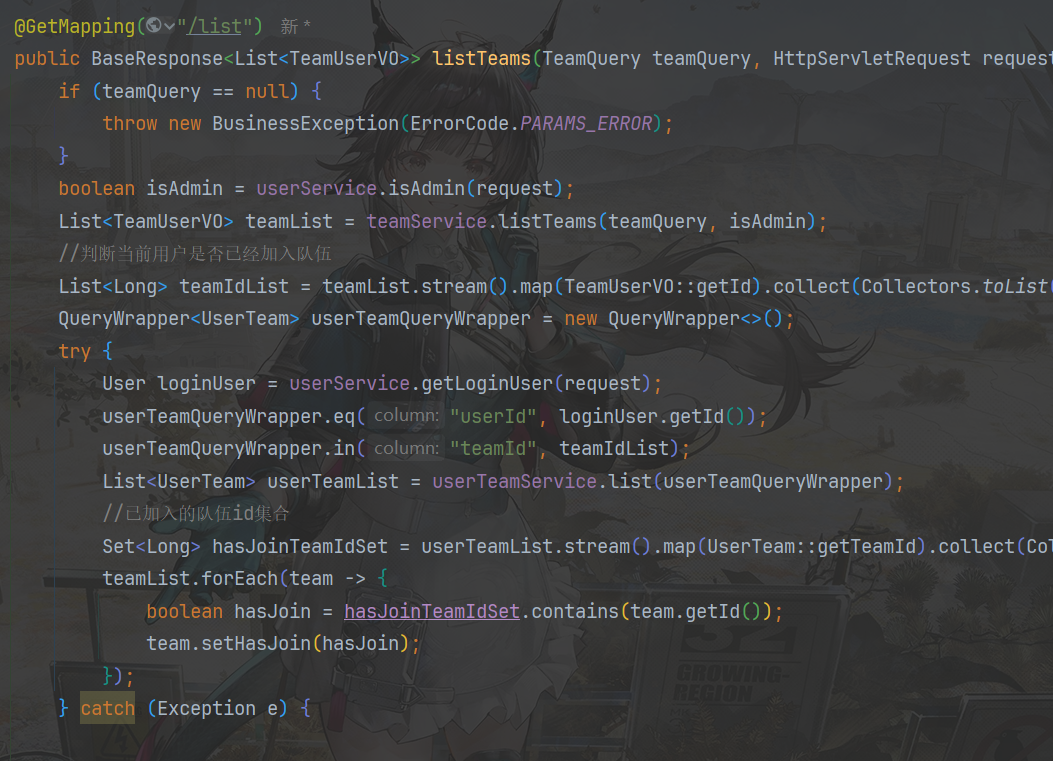
- 复用listTeam方法,只新增查询条件,不做修改(开闭原则)
修改个人页面排版,实现部分按钮对应功能。

第十一部分
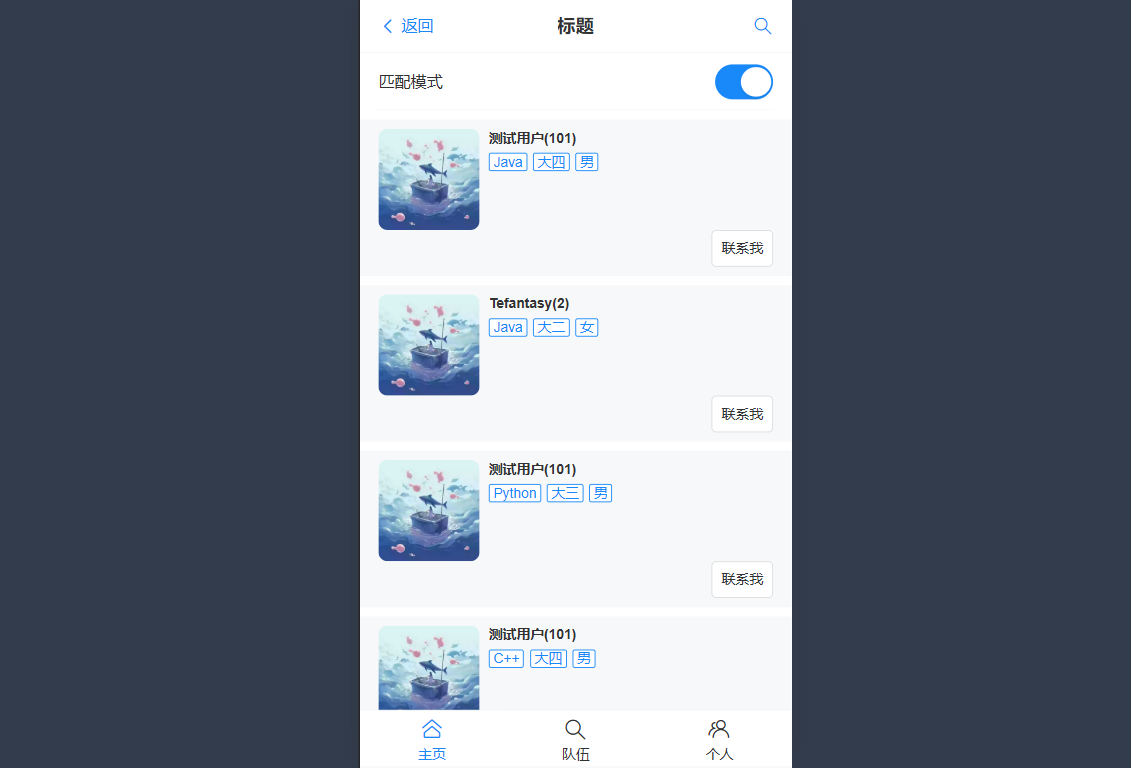
怎么匹配
- 匹配一个还是多个
- 多个
- 根据什么匹配
- 标签
- 找到共同标签最多的用户
- 共同标签越多,分数越高,越在前面
- 如果没有推荐到用户,就随机推荐几个(降级方案)
- 算法举例:

- 编辑距离算法:https://blog.csdn.net/tianjindong0804/article/details/115803158
- 最小编辑举例:字符串1最少通过多少次增删改操作变成字符串2
- 编辑距离算法:https://blog.csdn.net/tianjindong0804/article/details/115803158
- 匹配一个还是多个
怎么对所有用户匹配,取前几个
取出所有用户依次匹配(暴力破解)
优化方法:

大数据推荐是如何做的?
实现:

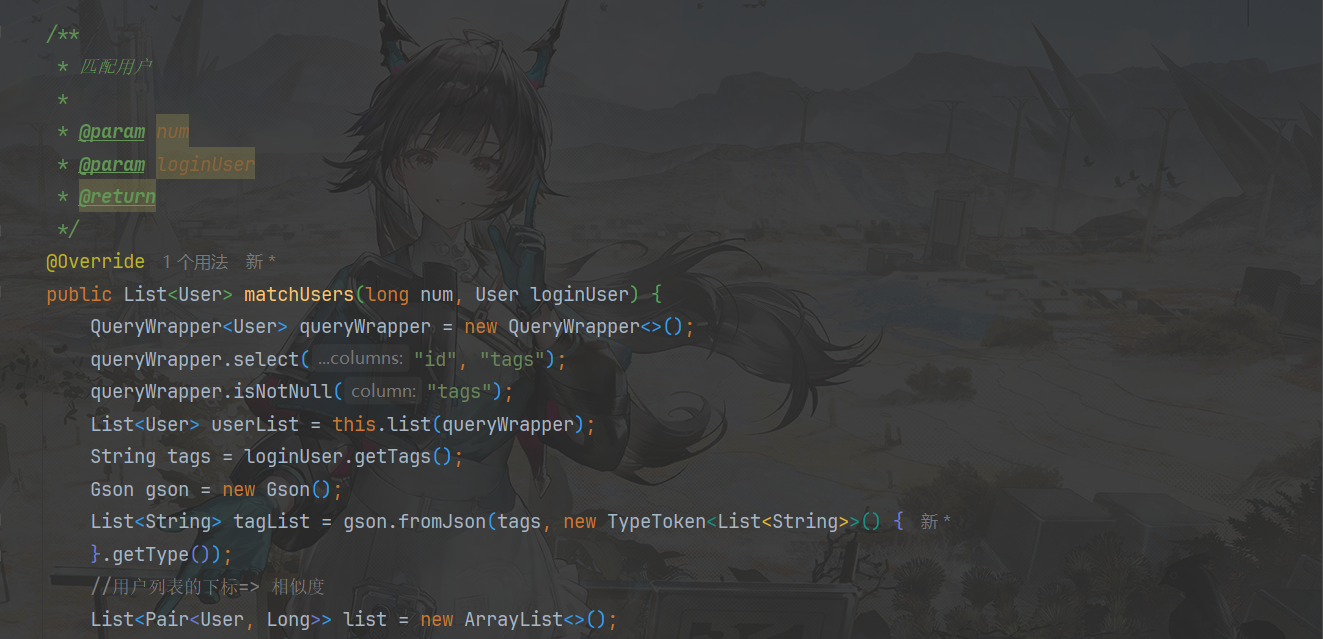
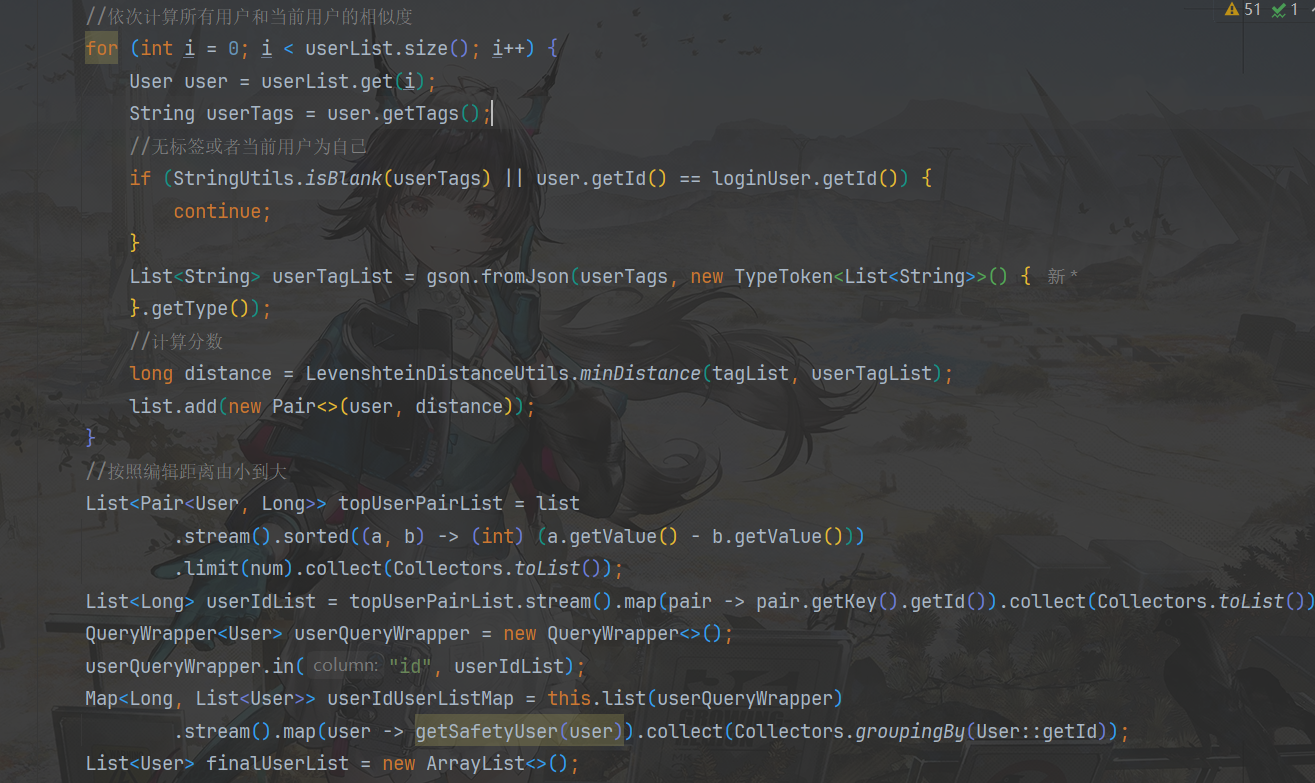

第十二部分
优化
- 前端页面优化
- 后端逻辑优化
- 前端页面优化