

寻梦算法学习平台项目总结
第一部分
技术选型
前端
- Vue3
- Vue-Cli脚手架
- Vuex状态管理
- Arco Design组件库
- 前端工程化:ESLint+Prettier+TypeScript
- Bytemd markdown富文本编辑器
- Monaco Editor代码编辑器
- OpenAPI前端代码生成
- ECharts可视化库
后端
- Java Spring Boot
- Java Spring Cloud
- MySQL数据库
- Docker容器
- RabbitMQ消息队列
前端工程化配置
代码美化设置
脚手架已经配置了代码美化,自动校验等,无需再次自行配置
但是需要在WebStorm里开启代码美化插件:
在Vue文件中执行格式化快捷键不报错,表示配置工程化成功。
脚手架自动整合了Vue-router。
引入组件
按照文档来
项目通用布局
新建一个布局,在app.vue中引入
在arco design组件库找布局,编排好相应的布局,填充内容
实现通用菜单
把菜单上的路由改成读取路由文件,更通用的动态配置。
全局状态管理
user模块
import { StoreOptions } from "vuex"; export default { namespaced: true, state: () => ({ loginUser: { userName: "未登录", role: "notlogin", }, }), actions: { getLoginUser({ commit, state }, payload) { commit("updateUser", { userName: "言梦" }); }, }, mutations: { updateUser(state, payload) { state.loginUser = payload; }, }, } as StoreOptions<any>;获取状态变量
const store = useStore(); console.log(store.state.user.loginUser.userName);修改状态变量
store.dispatch("user/getLoginUser", { userName: "言梦", role: "admin", });
权限管理

axios根据后端自动生成前端代码
openapi --input http://localhost:8101/api/v2/api-docs --output ./generated --client axios
生成后首先把基础路径改对

接着打开cookie

第二部分
优化页面布局
根据权限隐藏菜单
- routes.ts给路由新增一个标志位,用于判断是否隐藏
- 不要用v-for+v-if 去条件渲染元素,这样会先循环所有元素,导致性能浪费。最好先过滤只需要展示的数组。
全局权限管理
定义权限
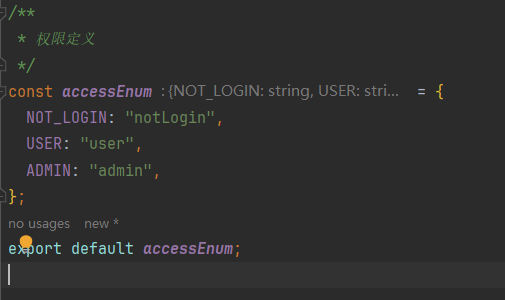
抽离权限判断方法。
import accessEnum from "@/access/accessEnum";
/**
* 判断当前用户是否具有某个权限
* @param loginUser 当前登录用户
* @param needAccess 需要有的权限
* @return boolean 有无权限
*/
const checkAccess = (loginUser: any, needAccess = accessEnum.NOT_LOGIN) => {
//获取当前登录用户具有的权限
const loginUserAccess = loginUser?.userRole ?? accessEnum.NOT_LOGIN;
//如果当前用户登录需要的权限为未登录
if (needAccess === accessEnum.NOT_LOGIN) {
return true;
}
//如果当前用户登录需要的权限为用户
if (needAccess === accessEnum.USER) {
//如果当前用户的权限为未登录
if (loginUserAccess === accessEnum.NOT_LOGIN) {
return false;
}
}
//如果当前用户登录需要的权限为管理员
if (needAccess === accessEnum.ADMIN) {
//如果当前用户的权限不为管理员
if (loginUserAccess !== accessEnum.ADMIN) {
return false;
}
}
return true;
};
export default checkAccess;
修改菜单,实现动态根据权限过滤菜单:
注意使用计算属性,是为了当用户登录信息发生变更时,触发菜单栏的动态更改。
const visibleRoutes = computed(() => { return routes.filter((item, index) => { if (item.meta?.hideInMenu) { return false; } if ( !checkAccess(store.state.user.loginUser, item?.meta?.access as string) ) { return false; } return true; }); });
预留全局项目入口
/**
* 全局初始化函数,有全局单次调用的代码,都可以写在这里
*/
const doInt = () => {
console.log("hello,欢迎来到我的毕业设计~");
};
onMounted(() => {
doInt();
});
后端初始化
问题:出现 java.nio.charset.MalformedInputException: Input length = 1错误大概率是编码问题。
参考:https://blog.csdn.net/twotwo22222/article/details/124605029
前后端联调以及登录注册页面设计
问题:在app.vue.中route无法获取到path
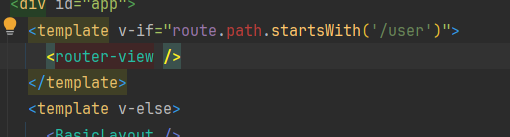
解决:参考https://blog.csdn.net/Wildness_/article/details/123003718
更深层次的原因是useRouter()和useRoute()的区别
参考:https://juejin.cn/post/7116720209502683172
前端页面登陆注册
支持多套页面布局
{ path: "/user", name: "用户", component: UserLayout, children: [ { path: "/user/login", name: "用户登录", component: UserLoginView, }, { path: "/user/info", name: "用户信息", component: UserInforView, }, { path: "/user/register", name: "用户注册", component: UserRegisterView, }, ], meta: { hideInMenu: true, }, },新建响应子路由页面,然后进行引入。
在app.vue中根据页面区分多套布局。
第三部分
梳理功能
库表设计
判题相关的配置以及判题用例保存为json对象,优点:便于扩展,只需要修改json内部字段,不需要修改数据库表。
判题状态 0-待判题,1-判题中,2-成功,3-失败
索引小知识:


后端接口开发(题目,题目提交模块)
根据功能设计库表
自动生成对数据库的基本增删改查(mapper和service层的基本功能)
编写Controller层,实现基本的增删改查和权限校验
根据业务定制开发新的/编写新的代码
业务前缀:

定义VO类

以及其他的部分(写的太累了,小略一下)
第四部分
引入整合要用到的插件
makedown编辑器
整合bytemd编辑器https://github.com/bytedance/bytemd
阅读文档,完成引入
代码编辑器
安装编辑器
整合
先安装monaco-editor-webpack-plugin
在vue-cli中引入monaco代码编辑器
const { defineConfig } = require("@vue/cli-service"); const MonacoWebpackPlugin = require("monaco-editor-webpack-plugin"); module.exports = defineConfig({ transpileDependencies: true, chainWebpack(config) { config.plugin("monaco").use(new MonacoWebpackPlugin({})); }, });
monaco edtor 在读写值的时候,要使用toRow(编辑器实例)的语法来执行操作,否则会卡死。
开发页面
创建题目页面(√)
管理题目页面(√)
注意router和route的区别
页面复用,更新题目页面(√)
第五部分
问题修复
- 修复分页改变页面不改变的问题:
在分页页号改变时,触发@page-change事件,通过改变searchParams的值,并且通过watchEffect监听searchParams的改变,然后执行loadData重新加载,实现页号变化时触发数据的重新加载。
修复刷新页面未登录
修改access/index.ts中的获取用户登录信息,把登录后的信息更新到 loginUser变量上
页面列表搜索页
- 自定义表格渲染
使用插槽
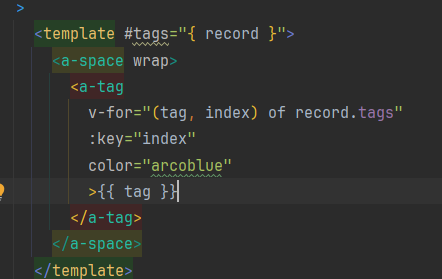
自定义通过率
使用模板语法自动计算
创建时间
使用moment库。
编写搜索表单,使用form的layout=inline布局,让用户的输入和searchParams同步,并且给提交按钮绑定修改searchParams,触发loadData查询的代码,从而被watchEffect监听到
题目浏览页
- 首先定义动态参数路由,开启props为true,可以在页面的props中直接获取动态参数(题目)
- 定义布局(左侧题目信息,右侧代码编辑器)
代码沙箱开发
定义代码沙箱接口,提高通用性
使用工厂模式,根据用户传入的字符串参数,来生成对应的代码沙箱实现类。
此处使用静态工厂模式
Github按句号可以进入web editor 方便查看代码
参数配置化,把一些可以交给用户定义的字符串,写下配置文件中。这样只要改配置文件。
application.yml 配置文件中指定变量
在Spring的Bean中通过@Value注解读取
使用链式可以更方便的给对象赋值
判题服务完整业务流程
累,略
细心,再细心。
因为少了一个取反以及错误的ErrorCode,导致最后没成功。

第六部分
代码沙箱两种实现:
Java原生实现
- 代码沙箱需要:接收代码=>编译代码(javac)=>运行代码(java)
编译后乱码:
终端默认编码GBK,chcp是936
javac -encoding utf-8 %s
用编译时加上-encoding utf-8的字样来解决
规范限制用户输入的类名,统一为Main
核心流程实现:
程序操作命令行,编译代码
Java进程执行管理类:Process
将用户代码保存为文件
编译代码,得到class文件
执行代码,得到输出结果
收集整理输出结果
文件清理
错误处理:提升程序健壮性
具体步骤
1. 用户代码保存为文件
引入Hutool工具类
新建目录,每个用户的代码都存放在独立目录下,便于维护
2. 用户代码保存为文件
java执行程序
Process process = Runtime.getRuntime().exec(compileCmd);
java获取控制台的输出:通过exitValue判断程序是否返回,从inputStream和errorStream获取控制台输出
process的waitFfor()函数:等待程序的执行,获取错误码。
编写工具类,执行进程,获取输出。
3. 执行程序
运行乱码问题:
java -Dfile.encoding=UTF-8 -cp %s Main %s
4. 整理输出
获取程序执行时间
使用最大值来统计时间,便于后续判题服务计算程序是否超时。
5. 文件清理
防止服务器空间不足
6. 错误处理
封装一个错误处理方法,当程序抛出异常时,直接返回错误响应
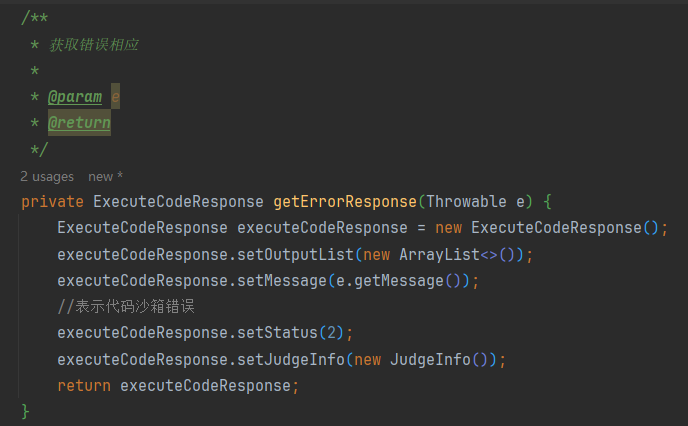
异常情况
1. 超时控制
通过创建一个守护线程,超时后自动终端process实现
2. 限制资源的分配
我们不能让每个Java进程的执行占用的JVM最大堆内存空间都和系统的一致,实际上应该小一点,比如说256MB.
在启动java时,可以指定JVM的参数:-Xmx256m(最大堆空间大小)-Xms(初始堆空间大小)
注:-Xmx参数,JVM的堆内存限制,不等同于系统实际占用的最大资源,可能会超出。
如果需要更严格的限制,要在系统层面去限制,而不是JVM层面的限制。
如果是Linux系统,可以使用cgroup来实现对某个进程的CPU内存等资源的分配
3. 限制代码 -黑白名单
先定义一个黑白名单。哪些操作是禁止的。
HuTool字典树工具类:WordTree,可以用更少的空间储存更多的敏感词汇,实现更高效的敏感词查找。
4. 限制用户操作权限
限制用户对文件,内存,CPU,网络等资源的操作和访问。
java安全管理器(Security Manager)是java提供的保护JVM,java安全的机制,可以实现更严格的资源和操作限制。
编写安全管理器,只需要继承SecurityManager。
5. 运行环境隔离
系统层面上,把用户程序封装到沙箱里,和宿主机隔离开。
用Docker技术。
第七部分
docker实现
查看命令用法:
docker --help查看具体子命令用法:
docker run --help从远程仓库拉取镜像
docker pull [OPTIONS] NAME[:TAG|@DIGEST]根据镜像创建容器实例
docker create [OPTIONS] IMAGE [COMMAND] [ARG...]查看容器状态
docker ps -a启动容器
docker start [OPTIONS] CONTAINER [CONTAINER...]查看日志
docker logs [OPTIONS] CONTATNER删除容器实例
docker rm [OPTIONS] CONTAINER [CONTAINER...]删除镜像
docker rmi [OPTIONS] IMAGE [IMAGE...]
1. JAVA操作docker
使用Docker-Java:https://github.com/docker-java/docker-java/blob/main/docs/README.md
引入依赖
<!-- https://mvnrepository.com/artifact/com.github.docker-java/docker-java -->
<dependency>
<groupId>com.github.docker-java</groupId>
<artifactId>docker-java</artifactId>
<version>3.3.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.github.docker-java/docker-java-transport-httpclient5 -->
<dependency>
<groupId>com.github.docker-java</groupId>
<artifactId>docker-java-transport-httpclient5</artifactId>
<version>3.3.0</version>
</dependency>
DockerClientConfig:用于定义初始化DockerClicent的配置(类比MySQL的连接,线程数配置)
DockerHttpClient:用于向Docker守护进程(操作Docker的接口)发送请求的客户端,低层封装(不推荐使用),你要自己构建请求参数(简单理解成JDBC)
DockerClient(推荐):才是真正的和Docker守护进程交互的,最方便的SDK,高层封装,对DockerHttpClient再进行了一层封装(理解成MyBatis),提供了现成的增删改查。
2. 创建容器,上传编译文件
注意,如果启动不成功:
在compiler的VM虚拟机配置一栏添加如下命令:
-Djdk.lang.Process.launchMechanism=vfork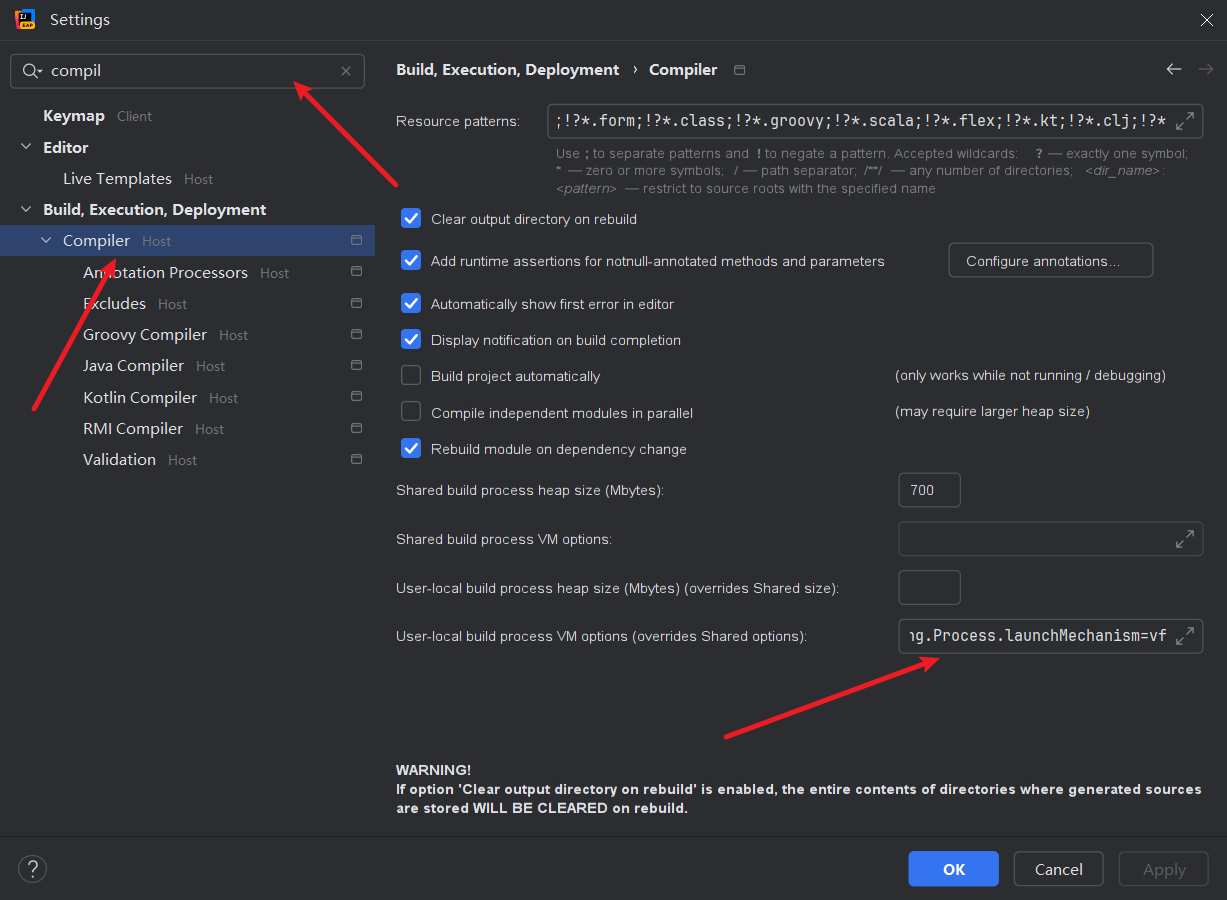
查看docker用户组:
cat /etc/group |grep 'docker'添加用户组:
groupadd docker在docker的用户组中添加当前用户:
gpasswd -a ${USER} docker刷新用户组缓存
newgrp docker启动docker
systemctl start docker检查运行状态
systemctl status docker
自定义容器两种方式:
- 在已有镜像的基础上再扩充:比如拉取现成的Java环境(包含JDK),再把编译后的文件复制到容器里
- 完全自定义容器
创建容器时,可以指定文件路径(Volumn)映射,作用是把本地的文件同步到容器中,可以让容器访问。(也可以叫容器挂载目录)
HostConfig hostConfig=new HostConfig();
hostConfig.setBinds(new Bind(userCodeParentPath,new Volume("/app")));
3. 启动容器,执行代码
Docker执行容器命令(操作已启动容器):
docker exec [OPTIONS] CONTAINER COMMAND [ARG...]
测试
docker exec [容器名] java -cp /app Main 1 3
注意,要把命令按照空格拆分,作为一个数组传递,否则可能被识别为一个字符串,而不是多个参数。
成功!
尽量复用之前的ExecuteMessage模式,在异步接口中填充正常和异常信息
获取程序执行时间:和java原生一样,使用StopWatch在执行前后统计时间。
获取占用内存:
定义一个周期,定期地获取程序内存
final long[] maxMemory = {0L};
StatsCmd statsCmd = dockerClient.statsCmd(containerId);
ResultCallback<Statistics> statisticsResultCallback = statsCmd.exec(new ResultCallback<Statistics>() {
@Override
public void onNext(Statistics statistics) {
System.out.println("内存占用:" + statistics.getMemoryStats().getUsage());
maxMemory[0] =Math.max(statistics.getMemoryStats().getUsage(), maxMemory[0]);
}
@Override
public void onStart(Closeable closeable) {
}
@Override
public void onError(Throwable throwable) {
}
@Override
public void onComplete() {
}
@Override
public void close() throws IOException {
}
});
statsCmd.exec(statisticsResultCallback);
第八部分
设计模式模板方法
模板方法:定义一套通用的执行流程,让子类负责每个执行步骤的具体实现
模板方法的使用场景:适用于有规范的流程,且执行流程可以复用
作用:大幅节省重复代码量,便于项目扩展,更好维护。
1.抽象出具体流程:
先复制具体的实现类,把代码从完整的方法抽离成一个一个子写法。
完整流程:
public ExecuteCodeResponse executeCode(ExecuteCodeRequest executeCodeRequest) {
List<String> inputList = executeCodeRequest.getInputList();
String code = executeCodeRequest.getCode();
String language = executeCodeRequest.getLanguage();
//1. 把用户代码保存为文件
File userCodeFile = saveCodeToFile(code);
//2. 编译代码,得到class文件
ExecuteMessage compileFileExecuteMessage = compileFile(userCodeFile);
System.out.println(compileFileExecuteMessage);
//3. 执行代码,得到输出结果
List<ExecuteMessage> executeMessageList = runFile(userCodeFile, inputList);
//4.收集信息输出信息
ExecuteCodeResponse outputResponse = getOutputResponse(executeMessageList);
//5.文件清理
boolean b = deleteFile(userCodeFile);
if (!b){
log.error("deleteFile error,userCodeFilePath={}",userCodeFile.getAbsolutePath());
}
return outputResponse;
}
- 定义子类的实现
给代码沙箱提供开放API
/**
*执行代码
* @param executeCodeRequest
* @return
*/
@PostMapping("/executeCode")
public ExecuteCodeResponse executeCode(@RequestBody ExecuteCodeRequest executeCodeRequest) {
if (executeCodeRequest==null){
throw new RuntimeException("请求参数为空");
}
return javaNativeCodeSandbox.executeCode(executeCodeRequest);
}
调用安全性
调用方与服务提供方约定一个字符串**(最好加密)**
优点:实现最简单,比较适合内部系统之间的互相调用
缺点:不够灵活,如果key变更或泄露,需要重启代码。
//定义鉴权请求头和密钥
private static final String AUTH_REQUEST_HEADER = "auth";
private static final String AUTH_REQUEST_SECRET = "secretKey";
@PostMapping("/executeCode")
public ExecuteCodeResponse executeCode(@RequestBody ExecuteCodeRequest executeCodeRequest, HttpServletRequest request,
HttpServletResponse response) {
//基本的认证
String authHeader = request.getHeader(AUTH_REQUEST_HEADER);
if (!AUTH_REQUEST_SECRET.equals(authHeader)) {
response.setStatus(403);
return null;
}
if (executeCodeRequest == null) {
throw new RuntimeException("请求参数为空");
}
return javaNativeCodeSandbox.executeCode(executeCodeRequest);
}
}
.header(AUTH_REQUEST_HEADER,AUTH_REQUEST_SECRET)
跑通整个流程
- 归类题目服务和题目提交服务
- 由于后端改了接口地址,前端需要重新生成接口调用代码
openapi --input http://localhost:8101/api//v2/api-docs --output ./generated --client axios
还需要更改前端调用的controller
- 后端调试
- 提交列表页面
- 新建路由
- 编写对应的页面
第九部分
学习系统部分
学艺不精,先实现,后续优化。
在视频学习上,采用了b站的HTML嵌入代码,通过跳转页面时在对应位置拼接字符串拼出正确的地址。来实现不同视频的播放。
在证书获取部分,在后端根据当前登录用户的用户昵称,通过填充pdf模板的表单,生成对应的pdf证书。因为在向前端传输的过程中,很多次导致乱码。并花费了大量时间试图解决,无果。只得转换思路,在后端将其转换为png图片,然后往前端传输。待后续更深入些再来解决。
前端方面做了鉴权。获取证书的标准是做完题库所有题目。后续会添加对视频学习数量的判断,学习视频会出现对应题目/推荐题目,对于题目表会扩充字段。双重标准全部通过,才可获取证书。
对应数据表的增删改查
附一张学习表的图:
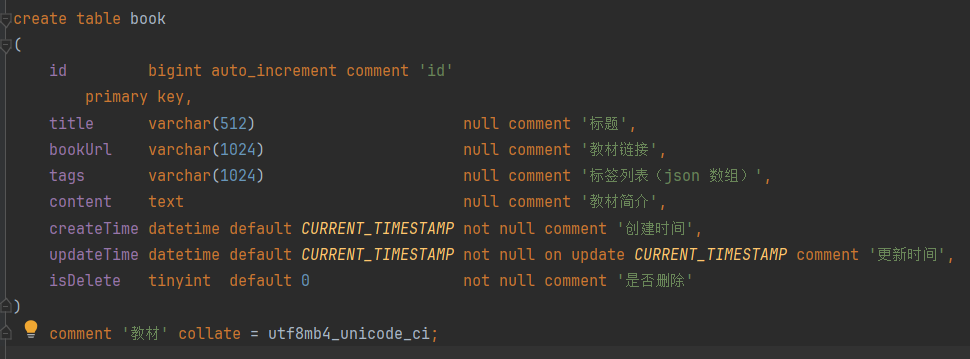
第十部分
讨论部分
评论回复功能后续优化,先实现了一个简陋版本。
添加了讨论区,对帖子的搜索,帖子采取倒序排列。帖子对应嵌套折叠列表为评论区。所发表的评论为倒序排列
完善了每道题目对应的讨论部分,只会显示对应题目的评论。做题页面实现题解的显示,分为官方以及其他。
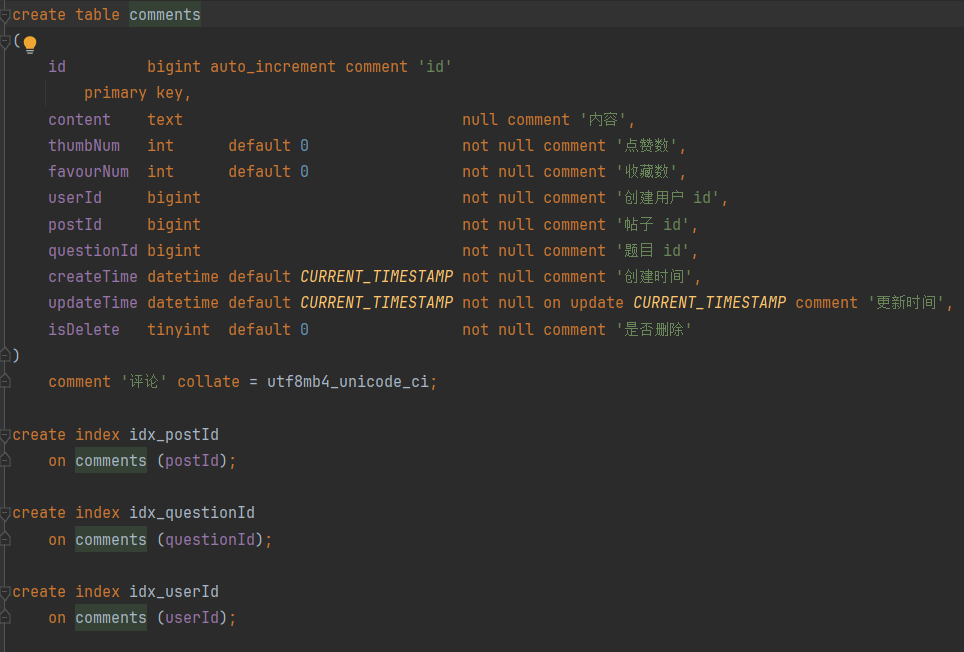
对应数据表的增删改查
附评论表的图
第十一部分
数据统计部分
- 这里交给了前端进行过滤。通过获取后端题目提交表的所有信息,根据创建时间进行过滤,得到当日的做题通过数量,以及总体的做题通过数量。进行对应的展示。
第十二部分
单体项目改造微服务
什么是微服务
服务:提供某类功能的代码
微服务:专注一提供某类特定功能的代码,而不是把所有的代码全部放到同一个项目里。会把整个大的项目按照一定的功能,逻辑进行拆分,拆分为多个子模块,每个子模块可以独立运行。独立负责一类功能,子模块之间相互调用,互不影响。
微服务实现技术
spring cloud
Dubbo
RPC
本质上是通过HTTP,或者其他的网络协议进行通讯来实现的。
微服务几个重要的实现因素:服务管理,服务调用,服务拆分。
spring cloud alibaba
本质:实在spring cloud的基础上,进行了增强,补充了一些额外的能力,根据阿里多年的业务沉淀做了一些定制化的开发。
注意:选择对应的版本
Nacos:集中存管项目中所有服务的信息,便于服务之间找到彼此同时,还支持集中存储真个项目中的配置。
改造前思考:
从业务需求出发,思考单机与微分布式的区别
用户登录:改造为分布式登录

改造分布式登录
微服务的划分

(findream-backend-gateway)
公共模块:
- common公共模块(findream-backend-common)
- model模型模块(findream-backend-model)
- 公用接口模块(findream-backend-service-client)
- 用户系统(findream-backend-user-service :8102端口)
- 登录
- 注册
- 题库判题系统: (findream-backend-question-service:8103端口)
- 题目分类模块:用户能够根据不同的分类找到感兴趣的题目。
- 题目搜索模块:用户可以根据条件搜索和过滤题目。
- 答题功能模块:用户可以作答题目并获得结果。
- 判题功能模块:系统能够从消息队列获取判题任务,将代码提交给代码沙箱进 行判题,并根据预定的规则判断结果。(findream-backend-judge-service:8104端口)
- 代码沙箱模块:系统能够对获取到的代码进行编译运行,并输出运行结果,保 障代码运行安全性。
- 知识库学习系统: (findream-backend-study-service:8105端口)
- 视频学习模块:提供学习算法所需的概念、原理的视频资源。
- 知识证书模块:为用户提供正式的认可和奖励机制。
- 论坛交流系统: (findream-backend-talk-service:8106端口)
- 帖子发布和浏览:用户可以发布新的帖子,并浏览其他用户发布的帖子。
- 评论:用户可以对帖子进行评论互动。
- 搜索和过滤:用户可以使用搜索功能查找特定的帖子或主题。
- 数据统计系统:
- 每日做题统计模块:对用户每日题目答题情况进行统计,实现可视化图表展示。
- 总体做题数据统计模块:对用户总体题目答题情况进行统计,实现可视化图表 展示。
- 用户通过数排行榜模块:对用户做题通过数进行排行
- 题目通过数排行榜模块:对题目通过数进行排行
- 后台管理系统:
- 用户信息管理模块:管理员可以对普通用户和管理员用户信息进行增删改查 操作。
- 题目信息管理模块:管理员可以对题库的题目信息进行增删改查操作。
- 论坛信息管理模块:管理员可以对论坛用户发布的帖子信息和评论进行增删 改查操作。
- 知识库信息管理模块:管理员可以对知识库信息进行增删改查操作。
路由划分
用户服务:
/api/user
/api/user/inner(内部调用,网关层面要限制)
题目服务:
/api/question(也包括题目提交信息)
/api/question/inner(内部调用,网关层面要限制)
判题服务:
/api/judge
/api/judge/inner(内部调用,网关层面要限制)
学习服务:
/api/study(包括获取证书)
/api/study/inner(内部调用,网关层面要限制)
交流服务:
/api/talk
/api/talk/inner(内部调用,网关层面要限制)
管理服务:
/api/manage
/api/manage/inner(内部调用,网关层面要限制)
Nacos注册中心启动
版本:2.2.0!!!
https://nacos.io/zh-cn/docs/quick-start.html
新建工程
spring cloud有非常多的依赖。不建议照搬或者自己配置。
建议脚手架创建项目https://start.aliyun.com/
给项目增加全局依赖配置文件
补充cloud的依赖,版本要对应。
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-dependencies</artifactId> <version>2021.0.5.0</version> <type>pom</type> <scope>import</scope> </dependency>给各模块绑定子父关系

同步代码和依赖
(1)common公共模块(findream-backend-common)
在外层pom引入公共类
<!-- https://hutool.cn/docs/index.html#/-->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.8</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
</dependency>
<!-- https://github.com/alibaba/easyexcel -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>3.1.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.commons/commons-collections4 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-collections4</artifactId>
<version>4.4</version>
</dependency>
(2)model模块(findream-backend-model)很多服务公用的实体类。
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.2</version>
</dependency>
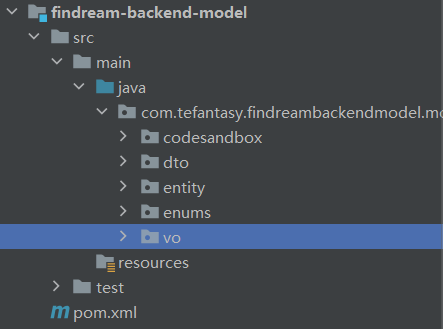
(3)公用接口模块(findream-backend-service-client)
先搬运所有service
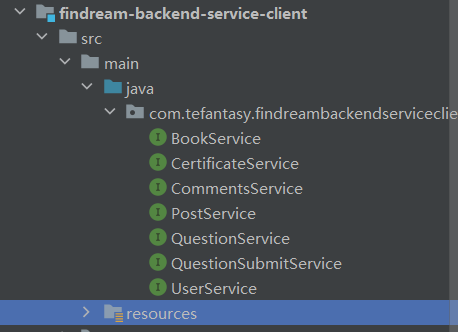
需要制定openfeign(客户端调用工具)的版本
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
<version>3.1.5</version>
</dependency>
(4)具体服务实现
给所有服务引入公共依赖
<dependency>
<groupId>com.tefantasy</groupId>
<artifactId>findream-backend-common</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>com.tefantasy</groupId>
<artifactId>findream-backend-model</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>com.tefantasy</groupId>
<artifactId>findream-backend-service-client</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
主类引入注解
引入application配置
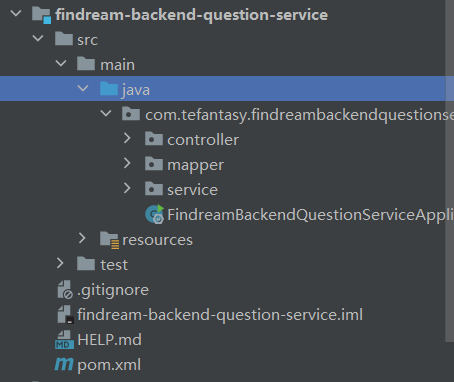
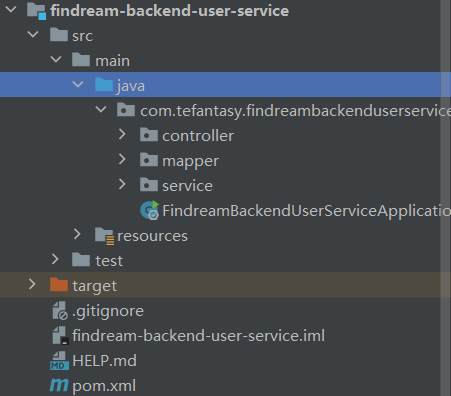
服务内部调用


从Nacos注册中心获取服务调用地址
梳理服务的调用关系,确定哪些服务(接口)需要给内部调用
用户服务:没有其他依赖
题目服务
userService.getById(userId);userService.getUserVO(user);userService.listByIds(userIdSet).stream()userService.isAdmin(loginUser));userService.getLoginUser(request);judgeService.doJudge(questionSubmitId);判题服务
questionService.getById(questionId);questionService.updateById(questionAccept);questionSubmitService.getById(questionSubmitId);questionSubmitService.updateById(questionSubmitUpdate);学习服务
userService.getLoginUser(request);userService.isAdmin(user)论坛服务
userService.getById(userId); userService.getUserVO(user); userService.listByIds(userIdSet); userService.getLoginUser(request); userService.isAdmin(user)确认要提供哪些服务
用户服务:
userService.getById(userId); userService.getUserVO(user); userService.listByIds(userIdSet); userService.getLoginUser(request); userService.isAdmin(user)题目服务:
questionService.getById(questionId);questionService.updateById(questionAccept);questionSubmitService.getById(questionSubmitId);questionSubmitService.updateById(questionSubmitUpdate);判题服务:
judgeService.doJudge(questionSubmitId);实现client接口
开启openfeign的支持,把我们的接口暴露出去(服务注册到注册中心上),作为API给其他服务调用(其他服务从注册中心寻找)。
需要修改服务提供者的context-path的全局请求路径
server: address: 0.0.0.0 port: 8102 servlet: context-path: /api/user
注意事项:
要给接口的每个方法打上请求注解,注意区分Get、Post
要给请求参数打上注解,比如RequestParam、RequestBody
@RestController @RequestMapping("/inner")Feign Client 定义的请求路径一定要和服务提供方实际的请求路径保持一致
修改各业务服务的调用代码为feignClient
编写服务实现类,注意要和之前定义的客户端保持一致
开启Nacos的配置,让服务之间能够互相发现
所有模块引入Nacos依赖,然后然后给业务服务(包括网关)增加配置。
spring: cloud: nacos: discovery: server-addr:127.0.0.1:8848给业务服务项目启动类打上注解,开启服务发现,找到对应的客户端Bean的位置
@EnableDiscoveryClient @EnableFeignClients(basePackages = "com.tefantasy.findreambackendserviceclient.service")全局引入负载均衡器依赖
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-loadbalancer</artifactId> <version>3.1.5</version> </dependency>
7. 启动项目测试依赖能否完成调用
微服务网关
微服务网关:Gateway聚合所有的接口,统一接收处理前端的请求
为什么要用?
- 所有的服务端口不同,增大了前端调用成本
- 所有的服务是分散的,你可能需要集中进行管理、操作,比如集中解决跨域、鉴权、接口文档、服务的路由、接口安全性,流量染色限流。
- Gateway 是应用层网关:会有一定的业务逻辑。
- Nginx 是接入层网关:比如每个请求的日志,通常没有业务逻辑。
接口路由
统一的接收前端的请求,转发请求到对应的服务
如何找到路由?可以编写一套对应的路由配置,通过api地址前缀来找到对应的服务
application.yml代码
spring: cloud: nacos: discovery: server-addr:127.0.0.1:8848 gateway: routes: - id: findream-backend-user-service uri: lb://findream-backend-user-service predicates: - Path=/api/user/** - id: findream-backend-question-service uri: lb://findream-backend-question-service predicates: - Path=/api/question/** - id: findream-backend-judge-service uri: lb://findream-backend-judge-service predicates: - Path=/api/judge/** - id: findream-backend-study-service uri: lb://findream-backend-study-service predicates: - Path=/api/study/** - id: findream-backend-talk-service uri: lb://findream-backend-talk-service predicates: - Path=/api/talk/** application: name: findream-backend-gateway main: web-application-type: reactive server: port: 8101聚合文档
以全局视角集中查看管理接口文档
knife4j:https://doc.xiaominfo.com/docs/quick-start#spring-boot-2
(1)先给所有业务服务引入依赖,同时开启接口文档配置
<dependency> <groupId>com.github.xiaoymin</groupId> <artifactId>knife4j-openapi2-spring-boot-starter</artifactId> <version>4.4.0</version> </dependency>knife4j: enable: true(2)给网关配置集中管理接口文档
引入依赖:
<dependency> <groupId>com.github.xiaoymin</groupId> <artifactId>knife4j-gateway-spring-boot-starter</artifactId> <version>4.4.0</version> </dependency>映入配置:
knife4j: gateway: # ① 第一个配置,开启gateway聚合组件 enabled: true # ② 第二行配置,设置聚合模式采用discover服务发现的模式 strategy: discover discover: # ③ 第三行配置,开启discover模式 enabled: true # ④ 第四行配置,聚合子服务全部为Swagger2规范的文档 version: swagger2分布式Session登录
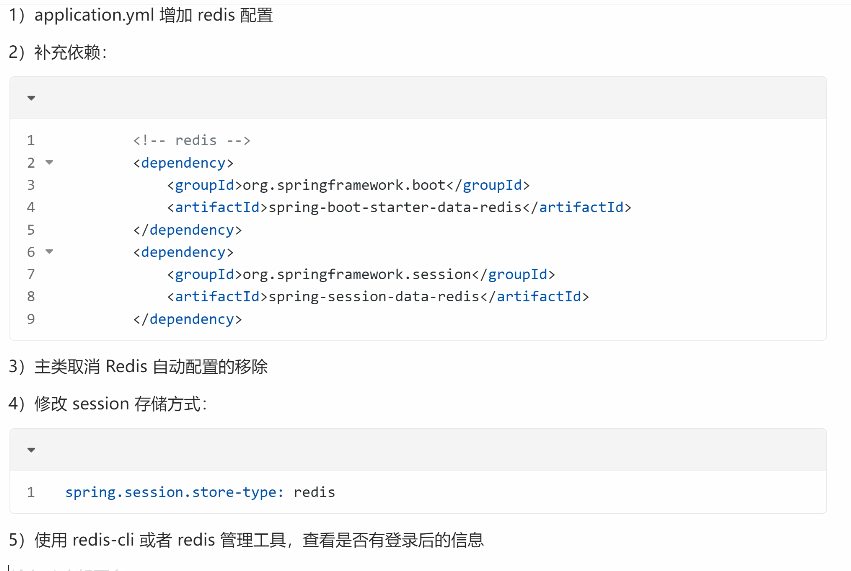
必须引入spring data redis 依赖:
<!-- redis --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> <dependency> <groupId>org.springframework.session</groupId> <artifactId>spring-session-data-redis</artifactId> </dependency>注意:添加redis依赖后接口文档报错,500。请刷新redis缓存。
跨域解决
@Configuration public class CorsConfig { @Bean public CorsWebFilter corsFilter(){ CorsConfiguration config=new CorsConfiguration(); config.addAllowedMethod("*"); config.setAllowCredentials(true); //todo 实际改为线下真实域名、本地域名 config.setAllowedOriginPatterns(Arrays.asList("*")); config.addAllowedHeader("*"); UrlBasedCorsConfigurationSource source=new UrlBasedCorsConfigurationSource(new PathPatternParser()); source.registerCorsConfiguration("/**",config); return new CorsWebFilter((CorsConfigurationSource) source); } }权限校验
可以使用Spring Cloud Gateway 的filter请求拦截器,接受到请求后根据请求的地址判断能否访问。
@Component public class GlobalAuthFilter implements GlobalFilter { private AntPathMatcher antPathMatcher = new AntPathMatcher(); @Override public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) { ServerHttpRequest serverHttpRequest = exchange.getRequest(); String path = serverHttpRequest.getURI().getPath(); //判断路径中是否包含inner,只允许内部调用 if (antPathMatcher.match("/**/inner/**", path)) { ServerHttpResponse response = exchange.getResponse(); response.setStatusCode(HttpStatus.FORBIDDEN); DataBufferFactory dataBufferFactory = response.bufferFactory(); DataBuffer dataBuffer = dataBufferFactory.wrap(("无权限").getBytes(StandardCharsets.UTF_8)); return response.writeWith(Mono.just(dataBuffer)); } return chain.filter(exchange); } }
消息队列解耦

安装rabbitmq
安装前置语言

选择对应版本
依赖引入
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-amqp</artifactId> </dependency>配置引入
spring: rabbitmq: host: localhost port: 5672 username: guest password: guest创建交换机
try { ConnectionFactory factory = new ConnectionFactory(); factory.setHost("localhost"); Connection connection = factory.newConnection(); Channel channel = connection.createChannel(); String EXCHANGE_NAME="code_exchange"; channel.exchangeDeclare(EXCHANGE_NAME,"direct"); //创建队列,随机分配一个队列名称 String queueName = "code_queue"; channel.queueDeclare(queueName,true,false,false,null); channel.queueBind(queueName,EXCHANGE_NAME,"my_routingKey"); }catch(Exception e){ log.error("消息队列启动失败"); }生产者代码
@Component public class MyMessageProducer { @Resource private RabbitTemplate rabbitTemplate; public void sendMessage(String exchange,String routingKey,String message){ rabbitTemplate.convertAndSend(exchange,routingKey,message); } }消费者代码
@Component @Slf4j public class MyMessageConsumer { @SneakyThrows @RabbitListener(queues = {"code_queue"}, ackMode = "MANUAL") public void receiveMessage(String message, Channel channel, @Header(AmqpHeaders.DELIVERY_TAG) long deliveryTag) { log.info("receiveMessage message={}", message); channel.basicAck(deliveryTag, false); } }
部分bug收集
在用户删除后,该用户创建的帖子还有评论因为获取的数据为空,导致报错。
解决:在获取列表的时候对拿到的用户数据进行判断,如果为空,新建一个userVO对象,将其用户名字和头像设定为注销的文字和头像。然后将其塞入该postVO对象中。评论同上。
//post if (user != null) { UserVO userVO = userService.getUserVO(user); postVO.setUser(userVO); } else { UserVO userN = new UserVO(); userN.setUserAvatar("https://work.lym0518.cn/image%E6%B3%A8%E9%94%80.jpg"); userN.setUserName("账户已注销"); postVO.setUser(userN); } //comments if (user != null) { UserVO userVO = userService.getUserVO(user); commentsVO.setUser(userVO); } else { UserVO userN = new UserVO(); userN.setUserAvatar("https://work.lym0518.cn/image%E6%B3%A8%E9%94%80.jpg"); userN.setUserName("账户已注销"); commentsVO.setUser(userN); }若选用docker代码沙箱注意一下改造:
- 及时删除容器,在全部执行完毕返回数据前删除。
dockerClient.removeContainerCmd(containerId).withForce(true).exec(); 否则会无限循环内存占用信息
改造入口,删除测试时的示例代码
改造执行命令,删除输入测试数据
String[] cmdArray = ArrayUtil.append(new String[]{"java", "-cp", "/app", "Main"}, inputArgsArray);- 对每次的输出结果进行结果两端的格式清除。删除多余的空格,换行等。
message[0] = new String(frame.getPayload()); message[0]=message[0].trim(); System.out.println("输出结果:" + message[0]);- 如果消息队列出问题了,上nacos看看。如果找不带dojudge方法。有可能是Judge的服务添加了mybitsPlus拦截器。删除。